Capítulo 7: Configuración de máquinas virtuales

7.1. Concepto de virtualización y máquinas virtuales
Los ordenadores han incrementado su rendimiento de forma vertiginosa a lo largo de los años.
La primera consecuencia de esta evolución fue el ahorro de espacio. Al principio, una empresa podía necesitar una habitación completa para albergar su servidor, pero un tiempo después, un ordenador equivalente podía ocupar la décima parte del espacio y había reducido de manera considerable su coste. De este modo, los ordenadores comenzaron a estar presentes en más empresas y en un mayor número de actividades dentro de ellas.
Además, se fue produciendo un aumento considerable de la potencia. Un ordenador podía realizar muchas más tareas que sus antecesores. Esto derivó en que, por cuestiones de rentabilidad, un mismo ordenador podía ofrecer varios servicios a su entorno.
Esto último, que en sí mismo era una gran noticia, escondía un gran inconveniente: varios servicios que originalmente habían sido concebidos para funcionar de manera independiente, de repente debían convivir en un mismo ordenador. En ocasiones, esto hacía que estos servicios tuviesen comportamientos inesperados, por la interacción con otros.
Del mismo modo, en muchas empresas se habían acostumbrado a tener un servidor distinto para cada departamento (Recursos humanos y nóminas, Ventas y finanzas, Investigación y desarrollo, …). Esto les aportaba ventajas, como el aislamiento y la seguridad, pero inconvenientes, como la duplicidad de información, las dificultades de consolidación de la información y el coste.
Al final, llegamos a un problema con dos vertientes contrapuestas: debemos concentrar los recursos para rentabilizar la inversión en hardware, pero debemos separarlos para asegurar su aislamiento, seguridad, etc.
La virtualización como solución al problema
La solución a este problema ha sido el software de virtualización, que parte de la idea de disponer de un único servidor y hacer que se comporte como varios.
 Una aplicación de virtualización es un software que utiliza una serie de técnicas avanzadas para abstraer las características físicas
del ordenador donde se instala y crear máquinas virtuales que producen la ilusión de ser plataformas hardware independientes.
Una aplicación de virtualización es un software que utiliza una serie de técnicas avanzadas para abstraer las características físicas
del ordenador donde se instala y crear máquinas virtuales que producen la ilusión de ser plataformas hardware independientes.
Por consiguiente, cada máquina virtual actúa como un ordenador independiente, sobre el que podremos instalar un nuevo sistema operativo con sus correspondientes aplicaciones y configuraciones. Además, al no tratarse de una máquina física, se puede hacer ver al sistema operativo un tipo de arquitectura o configuración diferente de la subyacente.
Las distintas máquinas virtuales que definamos sobre la misma máquina física, podrán ejecutar diferentes sistemas operativos, compartiendo todas ellas los recursos existentes. De esta forma, podremos disponer de varios ordenadores virtuales ejecutándose, a la vez, en el mismo ordenador físico.
Lógicamente, el número máximo de máquinas virtuales que podremos ejecutar de forma paralela estará limitado por los recursos disponibles en la máquina real.
El ordenador físico suele llamarse también anfitrión (host), hypervisor o monitor de la máquina virtual (VMM – Virtual Machine Monitor), mientras que también podemos referirnos a las máquinas virtuales como huéspedes o sistemas invitados (guest).
Aquí hablamos de la virtualización de sistemas operativos, pero estas mismas ideas podemos aplicarlas a la virtualización de redes, del almacenamiento, de aplicaciones o de escritorios, entre otros.
Tipos de virtualización
En realidad, el concepto general de virtualización representa diferentes métodos que han ido evolucionando, a lo largo del tiempo, con el fin de resolver problemas diferentes.
A continuación iremos mencionando los más representativos:
Emulación
El software de virtualización emula por completo el juego de instrucciones de un hardware que suele ser distinto del anfitrión.
Dicho de una forma simplista, el emulador recibe las instrucciones máquina de la arquitectura emulada y las traduce a las de la arquitectura del anfitrión para ejecutarlas . Una vez obtenida la respuesta, la traduce para el software invitado. Suele emularse, incluso, el funcionamiento del hardware específico de la arquitectura.
La consecuencia de todo este proceso es una pérdida de rendimiento muy considerable, por lo que no suele utilizarse en entornos de producción. Sin embargo, sí que resultan muy útiles en entornos de desarrollo para plataformas diferentes de la que estemos usando. Un ejemplo de esto es cuando se escriben programas para dispositivos móviles en ordenadores de escritorio. La pérdida de rendimiento se compensa con la diferencia de potencia de ambas plataformas.
 Algunos emuladores de Android para Windows son: Android Studio, BlueStacks, LDPlayer,
Genymotion, etc.
Algunos emuladores de Android para Windows son: Android Studio, BlueStacks, LDPlayer,
Genymotion, etc.
También podemos encontrar emuladores de iPhone para Windows o Mac, como Xcode, Xamarin, Appetize.io (basado en la web), etc.
Incluso podemos usar emuladores para volver a disfrutar de juegos para antiguas plataformas. Por ejemplo, para emular una GameBoy podemos usar BGB, GB Enhanced+ o RetroArch en Windows, o Mednafen en GNU/Linux… Pero es solo un ejemplo. En este campo podrás emular casi cualquier consola antigua.
Actividad 1: Instalar Genymotion
 Investiga cómo utilizar Genymotion. En particular, deberás completar las siguientes tareas:
Investiga cómo utilizar Genymotion. En particular, deberás completar las siguientes tareas:
Instalar Genymotion en tu máquina Ubuntu.
-
Comprobar cómo realizar la configuración inicial del dispositivo que quieras emular.
-
Ejecutar el dispositivo que acabas de crear e instalar una aplicación de tu elección. Esta aplicación no puede ser un juego y debe ser gratuita
Debes documentar detalladamente cada uno de los puntos anteriores.
 Una variante de esta idea la implementó Sun Microsystems
con su JVM (Java Virtual Machine). Se trataba de crear un software de emulación de una máquina ficticia sobre la que correrían los programas desarrollados en Java y compilados a bytecode (el código máquina
del emulador, es decir, de la Máquina Virtual Java). La idea es que existiera una versión de JVM para cada arquitectura anfitriona. De esta forma, los desarrolladores podrían escribir programas en Java que
luego ejecutarían en cualquier sistema, independientemente de su arquitectura.
Una variante de esta idea la implementó Sun Microsystems
con su JVM (Java Virtual Machine). Se trataba de crear un software de emulación de una máquina ficticia sobre la que correrían los programas desarrollados en Java y compilados a bytecode (el código máquina
del emulador, es decir, de la Máquina Virtual Java). La idea es que existiera una versión de JVM para cada arquitectura anfitriona. De esta forma, los desarrolladores podrían escribir programas en Java que
luego ejecutarían en cualquier sistema, independientemente de su arquitectura.
Más recientemente, Microsoft desarrolló .NET Framework, que parte de la misma idea. Además, separa definitivamente el lenguaje de programación y el bytecode obtenido tras la compilación. Esto permite trabajar en diferentes lenguajes y que el resultado se ejecute sobre el mismo emulador (.NET Framework).
Esta técnica ha evolucionado tanto en estos años que, en la actualidad, prácticamente no hay diferencia de rendimiento entre la ejecución de programas sobre emuladores o utilizando código nativo para la arquitectura sobre la que estemos trabajando.

Virtualización
La virtualización parece algo actual, pero su origen se remonta a finales de la década de 1960, cuando la empresa IBM desarrolló su gama de ordenadores IBM S/360. Se trataba de una serie de ordenadores que ofrecían un amplio abanico de potencia. El menos potente alcanzaba 0,034 MIPS y el mayor los 1,7 MIPS. Es decir, 50 veces más.
![]() Sin embargo, el objetivo era que toda la gama fuese compatible entre sí, permitiendo que los clientes pudieran migrar de un modelo
a otro sin perder todo su desarrollo.
Sin embargo, el objetivo era que toda la gama fuese compatible entre sí, permitiendo que los clientes pudieran migrar de un modelo
a otro sin perder todo su desarrollo.
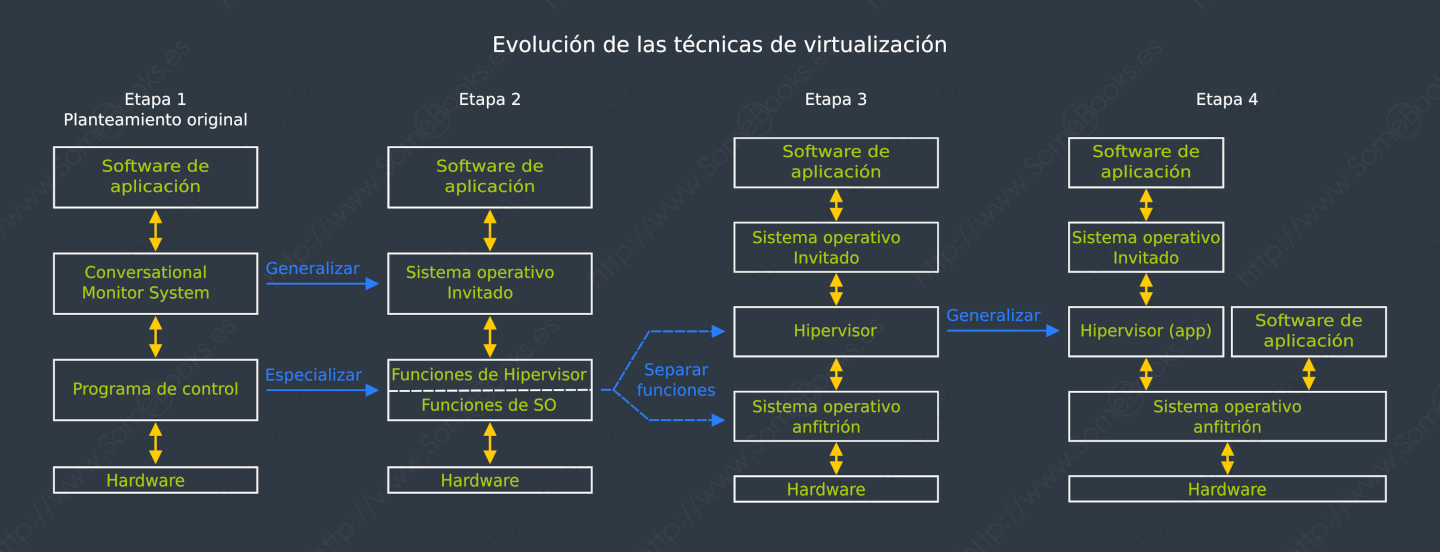
Para lograrlo, crearon una capa intermedia, entre el procesador y el sistema operativo, al que llamaron originalmente Programa de Control o CP (del inglés Control Program), que virtualizaba las interfaces hardware. Sobre él, podían ejecutarse varias instancias, completamente independientes de un sistema operativo estándar de IBM. Habitualmente se usaba CMS (Conversational Monitor System). Con este mecanismo, llegaron a poner en producción 14 máquinas virtuales de manera simultánea.
Además, los usuarios recibían el código fuente de este software (CP/CMS), que podían modificar, redistribuir y retornar los cambios a IBM.
Originalmente, se utilizó la palabra supervisor para referirse, de forma genérica, a esa capa intermedia pero, en la década de 1970, comenzó a utilizarse la palabra hipervisor (en inglés, hypervisor).
Con el paso del tiempo, el hipervisor se fue especializando e independizándose del sistema operativo, hasta el punto de funcionar como una aplicación dentro de este y usando, por ejemplo, archivos que se ofrecen como discos virtuales a los sistemas operativos invitados.
En 2005, Intel comenzó a comercializar procesadores que facilitaban la virtualización. Esta tecnología recibió el nombre de Intel VT-x. Un año más tarde, AMD hizo lo propio con sus procesadores, aunque en este caso, llamándola AMD-V.
Además, cuando hablamos de virtualización en ordenadores personales, existe un problema añadido: la variedad de hardware existente. Para resolverlo, el hipervisor emula dispositivos hardware ampliamente conocidos. Esto hace que el sistema invitado evite la dependencia del hardware real del anfitrión, usando controladores muy probados y estables.
Por otro lado, esa independencia simplificará la migración de un sistema invitado a un anfitrión distinto, o la sustitución de diferentes componentes hardware del anfitrión para mejorar su rendimiento o solventar una avería.
La opción inversa es la técnica conocida como Passthrough que consiste en crear un puente entre una máquina virtual y un dispositivo hardware físico con el objetivo de aprovechar todas sus características.
Esto es común cuando una máquina virtual debe acceder a un puerto PCI-e con acceso a un almacenamiento externo o a una GPU.
Paravirtualización
En la virtualización completa, el sistema operativo invitado no sabe que se encuentra instalado sobre una máquina virtual, lo que significa que todas las llamadas al hardware del sistema deben interceptarse y traducirse de forma adecuada por el hipervisor.
![]() En la paravirtualización, se modifica el núcleo del sistema operativo invitado para comunicarlo con el hipervisor.
Así, en lugar de hacer llamadas directas al hardware, las canaliza a través de éste. El resultado es una menor sobrecarga y, por lo tanto, un aumento de rendimiento del sistema virtualizado.
En la paravirtualización, se modifica el núcleo del sistema operativo invitado para comunicarlo con el hipervisor.
Así, en lugar de hacer llamadas directas al hardware, las canaliza a través de éste. El resultado es una menor sobrecarga y, por lo tanto, un aumento de rendimiento del sistema virtualizado.
Obviamente, también existe un gran inconveniente: La licencia de los sistemas operativos propietarios (como Windows o macOS) no permite la modificación y distribución de su núcleo para usarlos en un sistema paravirtualizado. Esto hace que, básicamente, la paravirtualización quede restringida a sistemas operativos libres, como GNU/Linux, FreeBSD, etc.
Otro inconveniente es la necesidad de modificación del núcleo del sistema, que requiere conocimientos profundos tanto del sistema anfitrión, como del sistema invitado y del software de paravirtualización.
En cuanto a las ventajas de la paravirtualización sobre la virtualización completa, podemos indicar las siguientes:
-
Presenta un rendimiento mayor.
-
No necesita las extensiones de virtualización de los procesadores, con lo que podemos usarla con cualquier procesador.
-
Puede utilizarse en arquitecturas diferentes de x86.
De cualquier modo, aunque las licencias de los sistemas operativos propietarios no permitan aplicar las técnicas de paravirtualización, éstas pueden utilizarse en otros propósitos relacionados con la virtualización completa.
Por ejemplo, prácticamente todos los sistemas operativos propietarios permiten la carga dinámica de controladores para la entrada/salida, el acceso a controladores de red, vídeo, etc. Si estos controladores utilizan técnicas de paravirtualización, nos estaremos beneficiando de ellas, de manera indirecta, incluso en este tipo de sistemas, aunque no podamos modificar su núcleo. Esta técnica es la que aplican, por ejemplo, los controladores de dispositivo virtio o las famosas VMware Tools.
Contenedores
![]() Los contenedores plantean una estrategia diferente a las anteriores. En este caso, el sistema operativo del anfitrión y el
de los invitados es el mismo, pero manteniendo aislados los procesos del anfitrión y los de cada invitado (con los del anfitrión y entre ellos). En este caso, los sistemas invitados se llaman contenedores.
Los contenedores plantean una estrategia diferente a las anteriores. En este caso, el sistema operativo del anfitrión y el
de los invitados es el mismo, pero manteniendo aislados los procesos del anfitrión y los de cada invitado (con los del anfitrión y entre ellos). En este caso, los sistemas invitados se llaman contenedores.
Para lograr este aislamiento, se crea un contexto de seguridad para cada contenedor, que alcanza los siguientes aspectos:
-
Nombre de equipo: Cada contenedor tendrá un nombre de equipo diferente.
-
Tablas de procesos: Cada contenedor tiene su tabla de procesos independiente.
-
Comunicación entre procesos: Los procesos de un contenedor solo podrán comunicarse con otros procesos que pertenezcan al mismo contenedor. Lo mismo ocurre con las zonas de memoria compartida.
-
Consumo de recursos: Normalmente pueden aplicarse cuotas máximas de consumo para los recursos compartidos (memoria, disco, tiempo de proceso, etc.)
-
Adaptadores de red: Normalmente, a cada contenedor se le asigna una dirección MAC e IP diferentes de modo que el kernel del sistema enruta cada paquete al contenedor adecuado. Incluso pueden aplicarse reglas de cortafuegos entre ellos.
-
Otros dispositivos hardware: Normalmente, los contenedores no tienen acceso directo al hardware. Será el anfitrión el encargado de planificar el acceso requerido por cada contenedor.
Como habrás imaginado, en este caso, es el sistema operativo quien se encarga de resolver la tarea, no siendo necesario el empleo de un hipervisor.
La gran ventaja de este planteamiento es el aumento de rendimiento, mientras que su mayor inconveniente es que estaremos supeditados a usar el mismo sistema operativo en el anfitrión y en todos los contenedores (al menos el mismo núcleo). Además, no está disponible en sistemas operativos propietarios.
Virtualización en la nube
El proceso anterior fue solo el principio. Poco a poco, grandes empresas como Amazon, Google, Oracle o Microsoft, entre otros, se dieron cuenta del potencial de la virtualización. Así nació el cloud computing (o computación en la nube).
Básicamente se trata de ofrecer capacidad de cálculo, bases de datos y otros tipos de almacenamiento, aplicaciones y otros recursos, a través de Internet, a cambio de un determinado coste.
En el contexto que nos ocupa, esto significa que un proveedor de cloud computing puede ofrecernos sus propios recursos hardware para almacenar nuestras propias máquinas virtuales y acceder a ellas desde cualquier parte del planeta.
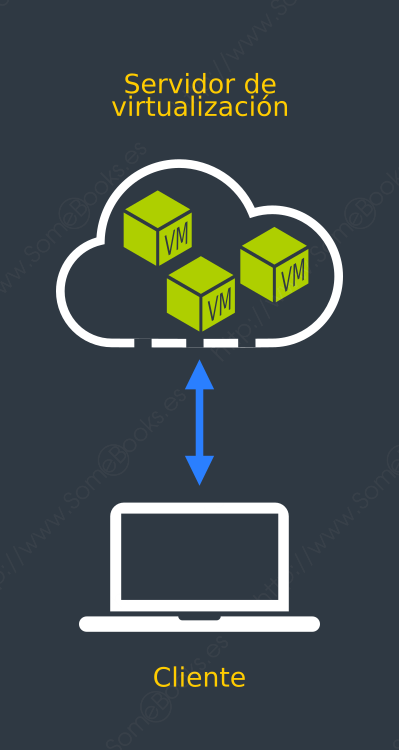
Esto nos permite olvidarnos de los requisitos que tienen los servidores de virtualización locales, como el mantenimiento, la reparación de averías, refrigeración, gastos de electricidad, seguridad física, etc.
Además dispondremos de flexibilidad a la hora de decidir el equipamiento. Es decir, contratamos la potencia a medida que la necesitamos, pudiendo aumentarla y disminuirla según los requerimientos.
Incluso podemos implementar modelos híbridos, donde una parte de la infraestructura de la empresa se encuentre virtualizada en la nube y otra, normalmente la más crítica, se implemente de forma local, para evitar eventuales problemas de falta de conexión.


