Capítulo 9: Administración de los sistemas operativos (Parte 2)

Gestión de dispositivos de almacenamiento
Cuando necesitamos más espacio de almacenamiento en disco, podemos recurrir a comprimir archivos, a moverlos a un dispositivo de almacenamiento externo o incluso a eliminar los que ya no necesitemos. Sin embargo, una buena alternativa consiste en añadir un nuevo disco duro a nuestro sistema. Los discos duros tienen una gran relación entre el precio y la capacidad de almacenamiento y son muy fáciles de instalar.
Si el ordenador no reconoce el disco que acabas de añadir, deberás consultar la documentación de tu BIOS para habilitar la autodetección de nuevos dispositivos.
Además, en la mayoría de los casos, el ordenador los detectará de forma automática y sólo habrá que configurar el sistema operativo para utilizarlos.
De hecho, en este apartado supondremos que la parte hardware ya está resuelta. Es decir, que ya has abierto el ordenador y has conectado correctamente un nuevo disco duro en su interior. Aquí nos centraremos en los ajustes que deberemos realizar en el sistema operativo para sacarle todo el rendimiento.
Configurar un disco nuevo en Windows
En Windows, configurar un disco que ha sido añadido en el interior del ordenador, o que se conecta a través de un puerto USB, FireWire o eSATA es prácticamente idéntico, salvo que los discos externos ya suelen venir particionados y formateados de fábrica (aunque siempre podremos borrar la estructura previa y comenzar de 0).
En cualquier caso, en Windows, podemos utilizar dos formas diferentes de configurar discos:
- Básica: Es la que utilizan la mayoría de los ordenadores personales, por ser los más sencillos de administrar. También es la configuración soportada por MS-DOS y por todas las versiones de Windows. De hecho, ya hicimos referencia en el capítulo 5 a algunas operaciones sobre discos que usaban este tipo de configuración. En particular, a los siguientes artículos:
En la configuración básica, cada partición (o volumen) es una entidad independiente, de modo que no puede compartir datos con otras particiones.
- Dinámica: Fue una configuración incorporada en los sistemas operativos de Micorsoft a partir de Windows 2000, que puede compartir un gran número de volúmenes (unos 2000), que pueden ser de distintos tipos:
- Simples (también llamados distribuidos): Permite unir varios discos para sumar sus capacidades y optimizar el espacio de almacenamiento. Sin embargo, los discos se comportarán del modo habitual. Este tipo de volumen puede ser reflejado, pero no es tolerante a fallos.
- Reflejados: Se crean dos copias idénticas de un volumen, apareciendo como una sola entidad. Cada escritura se replica en los discos espejo y pueden hacerse lecturas simultáneas de diferentes datos, lo que aumenta el rendimiento. Los diferentes discos pueden actuar de forma independiente (con diferentes controladoras), de modo que, si un disco falla, el sistema puede seguir funcionando a partir del que sigue activo. Esto aumenta la tolerancia a fallos.
Como es lógico, deben utilizarse discos de las mismas características. De lo contrario, se toma como referencia la capacidad del disco más pequeño.
Esta configuración equivale a RAID-1.
- Distribuidos: Utiliza varios discos para crear una sola unidad lógica, permitiendo usar el espacio disponible de una forma muy eficiente.Consigue una mejora de rendimiento, tanto en la lectura como en la escritura, debido a que las operaciones se llevan a cabo en discos diferentes de forma simultánea.
En esta configuración, los volúmenes no pueden ser reflejados y no es tolerante a fallos.
- Seccionados: Es una variante de la anterior. Aunque mejora su rendimiento, es más vulnerable a los errores de escritura.Esta configuración equivale a RAID-0.
- RAID-5: Distribuye los datos en tres o más discos, usando uno de ellos (que se va alternando) para almacenar información de paridad que permite la recuperación de datos cuando falla un disco. Por lo tanto, es tolerante a fallos. Mejora la eficiencia respecto a los anteriores, aunque el cálculo de la paridad penaliza ligeramente el rendimiento en la escritura.
En SomeBooks.es ya hemos incluido algunos artículos que hace referencia a discos dinámico:
Configurar un disco nuevo en Ubuntu 14.04 LTS
Ya comentábamos en el capítulo 6 que, en GNU/Linux, todos los dispositivos de almacenamiento conectados al ordenador se organizan en un mismo árbol de directorios. En él, cada volumen (cada partición) se integra en un punto concreto del árbol. De esta forma, podemos aumentar de forma sencilla, y transparente para el resto de usuarios del equipo, la capacidad de almacenamiento de éste.
Por ejemplo, eso fue lo que aprendimos a hacer en el artículo:
En él añadimos un nuevo disco al sistema para albergar todos los datos de los usuarios mientras que liberábamos todo el espacio que ocupaban en el disco principal.
RAID
En el capítulo 1, cuanto hablábamos de la jerarquía de memoria, ya comentábamos que, de entre todos los dispositivos de almacenamiento presentes en el ordenador, los que ofrecen un menor rendimiento son los discos duros.
Como una forma de paliar este problema se desarrolló el estándar RAID (del inglés, Redundant Array of Independent Disks), que podríamos traducir al español como conjunto redundante de discos independientes. Se trata de un sistema que almacena los datos utilizando diferentes dispositivos de almacenamiento (discos duros o unidades SSD) para crear un único volumen lógico.
Con RAID, el rendimiento se mejora de dos modos:
-
Si los datos buscados están duplicados en varios discos, podemos recurrir al que ofrezca mayor rendimiento.
-
Si los datos buscados se encuentran repartidos entre varios discos, podemos realizar la lectura en paralelo
Además, se puede incluir redundancia para mejorar la fiabilidad del soporte utilizado y compensar el aumento de la probabilidad de fallo, a medida que aumenta el número de dispositivos implicados.
El conjunto de discos podrá administrarse mediante un controlador hardware o mediante un software específico, pero de cualquier forma, el sistema lo verá como un solo volumen. Además, la capacidad del volumen podrá crecer de forma gradual, aumentando el número de dispositivos implicados.
A modo de ejemplo, en el siguiente artículo de SomeBooks.es te mostramos la implementación del nivel más básico de RAID por software:
Niveles RAID básicos
La definición básica de RAID consta de siete niveles, numerados de 0 a 6, a los que más tarde se fueron añadiendo algunos complementarios.
RAID 0 (o disk striping)
Distribuye los datos sobre los discos del conjunto de forma que permite la lectura o escritura de bloques en paralelo, aumentando considerablemente el rendimiento.
Los datos se organizan en bandas (strips, en inglés), que pueden corresponder, por ejemplo con bloques físicos o sectores. De este modo, el sistema operativo los maneja como si se tratara de un solo disco.
Las bandas se asignan de forma rotativa entre los discos que forman el conjunto. De este modo, cuando una lectura comprende varias bandas consecutivas, podrán leerse de forma paralela, aumentando considerablemente el rendimiento.
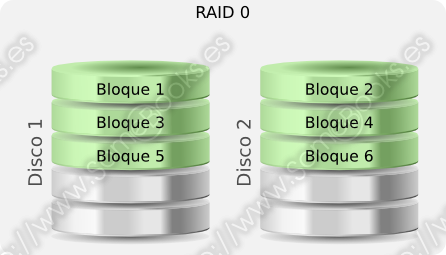
A diferencia de otros niveles RAID, en este caso no se ofrece redundancia. Esto implica que, si falla un disco, se perderían todos los datos y sólo nos quedaría recurrir a las copias de seguridad. A cambio, ofrece un rendimiento elevado, que aumenta al incrementar el número de discos, y el aprovechamiento de la capacidad de almacenamiento es máxima.
Existe una configuración llamada JBOD (del inglés, just a bunch of disks), que podríamos traducir como sólo un puñado de discos. No se trata de un nivel RAID propiamente dicho, porque crea un conjunto, con varios discos o particiones que se comporta como un volumen único.
El espacio disponible será la suma de sus componentes y, en su interior, los datos no quedan distribuidos, sino que se ocupa el espacio como si se tratara de un dispositivo individual.
La ventaja es que, cuando falla un disco, la información almacenada en el resto es recuperable. Sin embargo, su uso no mejora el rendimiento.
Se puede montar un volumen RAID 0 o JBOD con un solo disco aunque, en el caso de RAID 0, no mejoraría el rendimiento mencionado arriba.
RAID 1 (o mirroring)
A diferencia del caso anterior, que no contemplaba la redundancia, aquí, ésta es completa, ya que se obtiene duplicando todo el contenido almacenado. Sería como RAID 0, pero asignando cada banda a dos discos diferentes. De este modo, dispondremos de parejas de discos gemelos.
Evidentemente, su principal inconveniente es el coste.
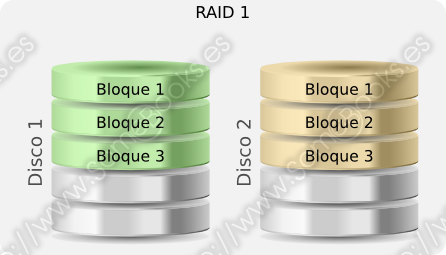
Sin embargo, en RAID 1, se pueden realizar lecturas en paralelo de dos bandas diferentes u obtener una banda del disco que ofrezca la mayor velocidad en cada momento (menor tiempo de búsqueda y latencia). Sin embargo, las escrituras serán duplicadas y se realizarán a la velocidad del dispositivo más lento de la pareja.
Además, cuando falla un disco, los datos siguen disponibles y basta con sustituir el disco dañado para que los datos puedan volver a duplicarse y recuperar la funcionalidad del conjunto. Cuando accedemos a los datos con un disco averiado, decimos que funciona en modo reducido.
Puedes aprender a implementar RAID 1 en Ubuntu siguiendo este artículo de SomeBooks.es:
- Crear un volumen RAID-1 con dos discos en Ubuntu 18.04 LTS.
- Recuperarse del fallo en un disco de un volumen RAID-1 sobre Ubuntu 18.04 LTS.
También aprendimos en el capítulo 3 cómo Configurar un volumen RAID durante la instalación de Ubuntu Server 18.04 LTS (en particular, esta configuración implementaba un RAID de nivel 1).
RAID 2
En este caso, el acceso a los discos se produce de forma paralela, normalmente sincronizando los ejes de los distintos discos para que sus cabezas se encuentren en la misma posición. De este modo, todos los discos participan en cada operación de E/S.
Como en los casos anteriores, los datos se organizan en bandas, aunque ahora suelen ser de un solo byte o palabra.
Se utilizan discos de paridad para almacenar códigos de corrección de errores en las posiciones correspondientes a las bandas de datos. El número de discos necesarios para esta labor corresponde con el logaritmo del número de discos de datos.

Suele aplicarse un código Hamming que puede corregir errores en un bit de forma inmediata, sin repercutir en la velocidad de lectura. También detecta errores en dos bits de una palabra.
Necesita discos con características especiales, por lo que no ha sido apenas implementado.
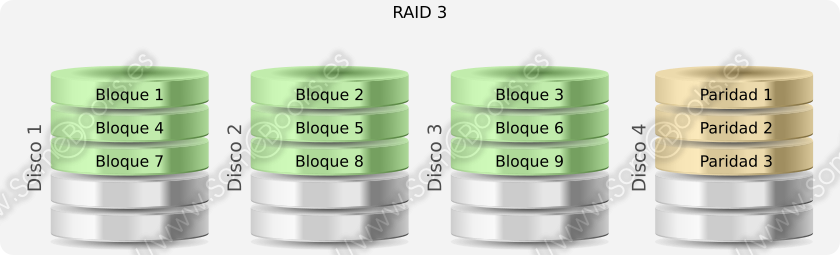
RAID 3
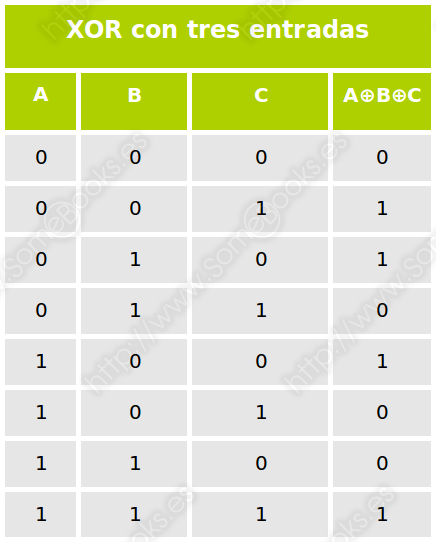
Su organización es parecida a RAID 2, pero sustituye el código de corrección de errores por un bit de paridad, que se calcula aplicando un operador OR Exclusivo (XOR) a las bandas de datos:
P = A ⊕ B ⊕ C
El operador XOR, cuando actúa sobre dos valores binarios, ofrece un resultado 1 si dichos valores son diferentes:
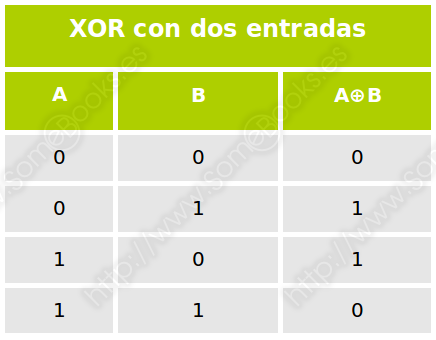
Cuando tiene más de dos entradas, el resultado es una suma de paridad. Es decir, si el número de entradas con valor 1 es impar, la salida será 1. En caso contrario, la salida será 0 (en realidad, es lo que sucede también cuando se tienen dos entradas). La tabla resultante para tres entradas es esta:
Esto hace que necesite únicamente un disco extra, con independencia del número de discos de datos.
Si falla un disco, la paridad permite reparar los datos y reconstruir toda la información una vez sustituido el disco. Por ejemplo:
B = A ⊕ C ⊕ P
Mientras el disco que ha fallado no haya sido sustituido y reconstruido, RAID 3 funcionará en modo reducido.
Como en RAID 2, el acceso es paralelo y utiliza bandas pequeñas.
RAID 4
A diferencia de RAID 2 y RAID 3, en RAID 4 los discos son independientes. Así, pueden atenderse distintas solicitudes al mismo tiempo.
Como antes, los datos se organizan en bandas, aunque son de mayor tamaño que en RAID 2 y RAID 3. Además, se obtiene una banda de paridad con las bandas correspondientes de cada disco de datos del mismo modo que en RAID 3.
Debemos tener en cuenta que una escritura implica un penalización motivada por la actualización de los datos de paridad, incluso cuando dicha escritura afecte sólo a uno de los discos del conjunto.
Como cada operación de escritura repercute sobre el disco de paridad, éste puede convertirse en un cuello de botella.
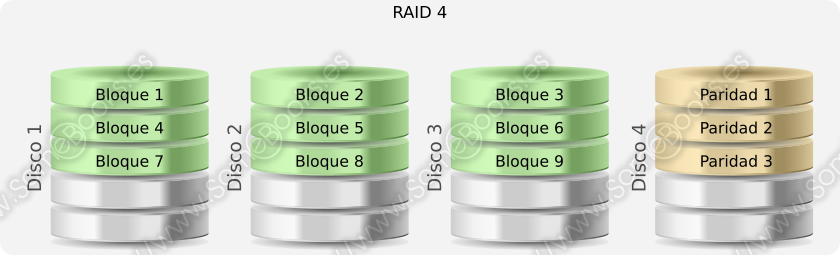
Aunque el esquema sea idéntico al de RAID 3, debemos recordar que, en este caso, las bandas son de mayor tamaño y los discos no se encuentran sincronizados.
RAID 5
Su organización es similar a la de RAID 4, pero alternando las bandas de paridad de forma rotativa entre los discos que forman el conjunto. De esta forma, se evita el posible cuello de botella que podía producirse en el disco de paridad de RAID 4.

Puedes aprender a implementar RAID 5 en Ubuntu siguiendo este artículo de SomeBooks.es:
RAID 6
Su estructura es como la de RAID 5, pero añadiendo un control de paridad complementario, que se almacena en la banda correspondiente de un disco independiente. Esto significa que necesitaremos un disco más.
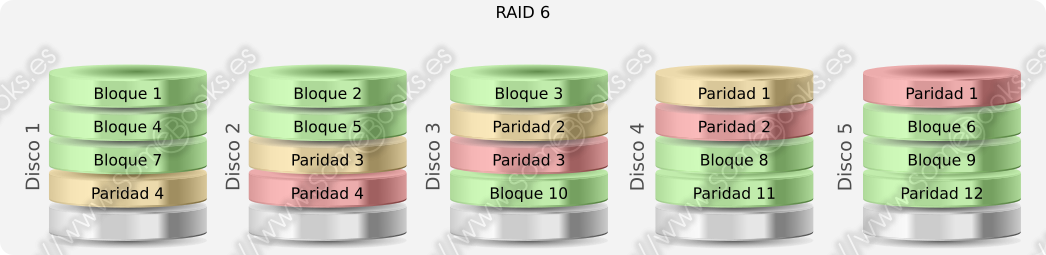
Su gran ventaja es que se podrán recuperar los datos aunque fallen dos discos al mismo tiempo (es decir, durante el periodo que tardaría en regenerarse el conjunto tras un fallo).
Su mayor inconveniente es que cada escritura conlleva una mayor penalización, ya que deberán calcularse dos bloques de paridad.
Otros niveles RAID
Además de los niveles básicos anteriores, a menudo podemos encontrar las siguientes variantes:
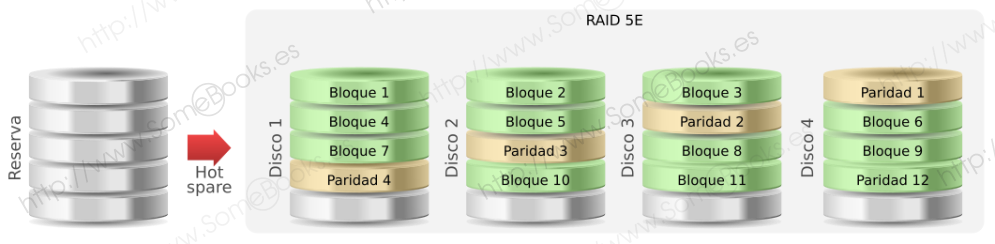
RAID 5E y RAID 6E
En realidad se trata de los niveles RAID 5 y RAID 6 estudiados más arriba, donde se incluyen discos de reserva. cuando los discos se encuentran conectados y listos para usar se denominan hot spare. Si están en modo espera reciben el nombre de standby spare.
La única aportación que ofrecen estas configuraciones es la rapidez de respuesta en el caso de que se produzca un fallo.
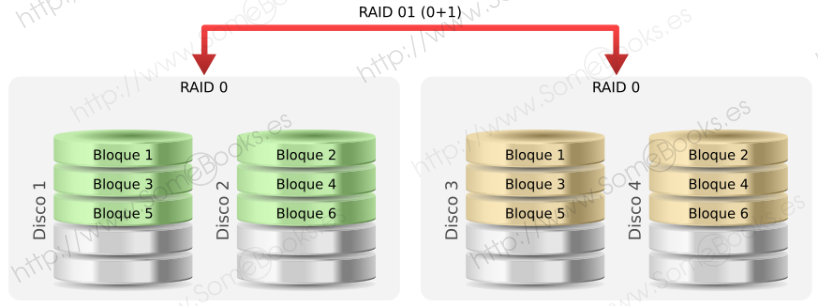
RAID 0+1
Es una anidación de RAID 0 y RAID 1 donde se crea un conjunto de discos entre los que se divide la información y a continuación se crea un espejo del volumen obtenido.
También suele llamarse RAID 01, pero no debe confundirse con RAID 1.
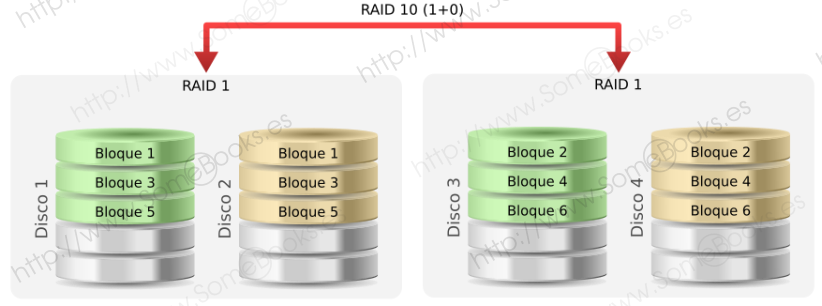
RAID 1+0
En este caso, la anidación se invierte, creando dos estructuras RAID 1 que, a continuación se unen entre sí creando un volumen RAID 0.
Muchas veces se encuentra como RAID 10.
RAID 30
De nuevo, se trata de un anidamiento donde se crean dos volúmenes RAID 3 que luego se unen para formar un RAID 0.

RAID 100
También suele llamarse RAID 10+0, porque une mediante un RAID 0 dos o más volúmenes RAID 10.

RAID 10+1
De forma parecida al anterior, se parte de un volumen RAID 10, del que se crea un espejo usando RAID 1.

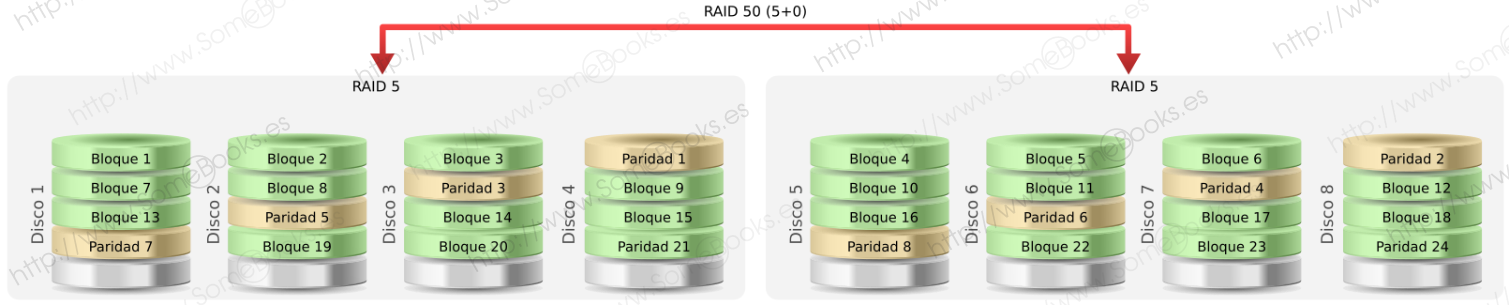
RAID 50
También suele llamarse RAID 5+0, porque une mediante un RAID 0 dos o más volúmenes RAID 5.
Niveles RAID propietarios
Además de todos los anteriores, existen algunos niveles RAID propietarios. Sin embargo, su estudio se escapa de los objetivos de este documento.
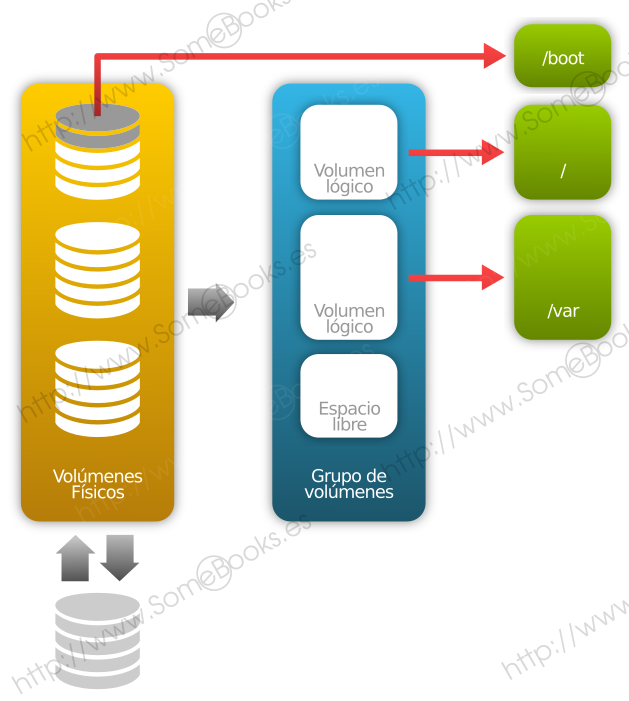
LVM
Otro tipo especial de partición es LVM (del inglés, Logical Volume Manager), que nos permite crear conjuntos de almacenamiento, llamados grupos de volúmenes, pudiendo aumentar y disminuir volúmenes lógicos de un modo muy flexible.
Estos volúmenes lógicos pueden crearse a partir de uno o varios discos físicos, y pueden ubicarse tanto en particiones estándar como en volúmenes RAID por software.
Un volumen lógico podrá extenderse añadiendo nuevos dispositivos físicos. De este modo, el sistema podrá adaptarse en el futuro a nuevos requerimientos.
En el contexto de LVM, debemos diferenciar los siguientes elementos:
-
Volumen físico (Physical Volume o PV): Es un disco duro físico, una partición o un volumen RAID por software, formateado como volumen físico LVM.
-
Grupo de volúmenes (Volume Group o VG): Está formado por uno o varios volúmenes físicos y actúa como un solo disco virtual. En el futuro, podrá extenderse añadiendo nuevos volúmenes físicos.
-
Volumen lógico (Logical Volume o LV): Representa un concepto similar a una partición en un sistema sin LVM. Se formateará con un sistema de archivos, se montará y permitirá el almacenamiento de datos.
La siguiente imagen lo muestra de forma gráfica:
A modo de ejemplo, en los siguientes artículos de SomeBooks.es te mostrábamos actividades relacionadas con volúmenes LVM:
Consideraciones finales
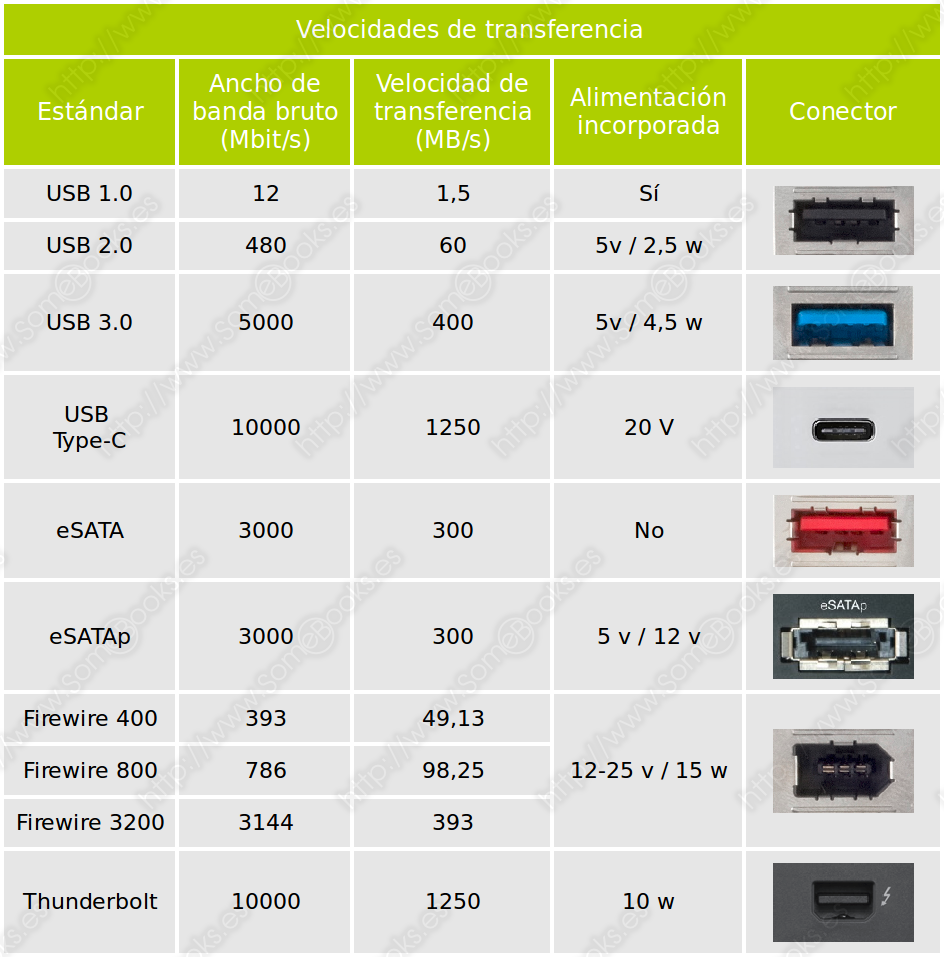
Si te decantas por un disco externo, debes tener muy en cuenta la velocidad de transferencia, que varía de forma importante de un estándar a otro. Esto puede hacer que no todos los sistemas sean adecuados para todos los usos. En la siguiente tabla se muestran las velocidades de transferencia de los principales tipos de conexiones: