Capítulo 5: Estructura del sistema operativo (Parte 2)

Gestión de archivos
En un sistema informático, aunque la memoria principal es indispensable para ejecutar procesos, no es un medio válido para el almacenamiento de los programas y los datos a largo plazo por dos motivos fundamentales:
-
Es volátil. Es decir, la memoria principal pierde todo su contenido cuando dejamos de administrar corriente eléctrica.
-
No es suficientemente grande. Recordemos que el precio de la memoria principal es muy superior al de la memoria secundaria (por unidad de almacenamiento). Esto hace inviable la creación de ordenadores que permitan guardar en memoria principal todos los archivos que ahora guardamos en memoria secundaria (textos, vídeos, sonido, imagen, bases de datos, etc.)
Para solventar estas carencias, se utilizan los dispositivos de memoria secundaria, como Discos duros, Unidades SSD, unidades USB, discos ópticos, etc.
El Sistema de archivos (en inglés, filesystem) es el componente del sistema operativo que se encarga de organizar el modo en el que se guardan los datos dentro de los dispositivos de almacenamiento secundario. Para llevar a cabo su tarea, desde un punto de vista lógico utiliza dos conceptos diferentes:
-
Archivo (o fichero): es una serie de bytes almacenados en un dispositivo de almacenamiento externo que, en conjunto, forman una unidad lógica. Cada archivo suele estar identificado en el sistema mediante un nombre y una extensión. Normalmente, el nombre sirve para identificar el contenido del archivo y la extensión para identificar el tipo al que pertenece (si es un documento, una imagen, etc.). Para evitar ambigüedades, no pueden existir dos archivos que tengan el mismo nombre y extensión dentro de la misma ubicación.
-
Carpeta (o directorio): es un modo de agrupar archivos, según el criterio del usuario, para facilitar su organización. Igual que los archivos, las carpetas tienen un nombre que las identifica. Para un sistema de archivos, una carpeta no es más que un archivo que contiene información sobre el modo en el que se organizan los datos. Como en el caso de los archivos, para evitar ambigüedades, no puede haber dos carpetas con el mismo nombre en la misma ubicación.
Como podemos suponer, la unidad de información con la que trabaja un sistema de archivos es, precisamente, el archivo.
Es frecuente que cada familia de sistemas operativos tenga sus propios sistemas de archivos. Por ejemplo, a continuación relacionamos los más conocidos:
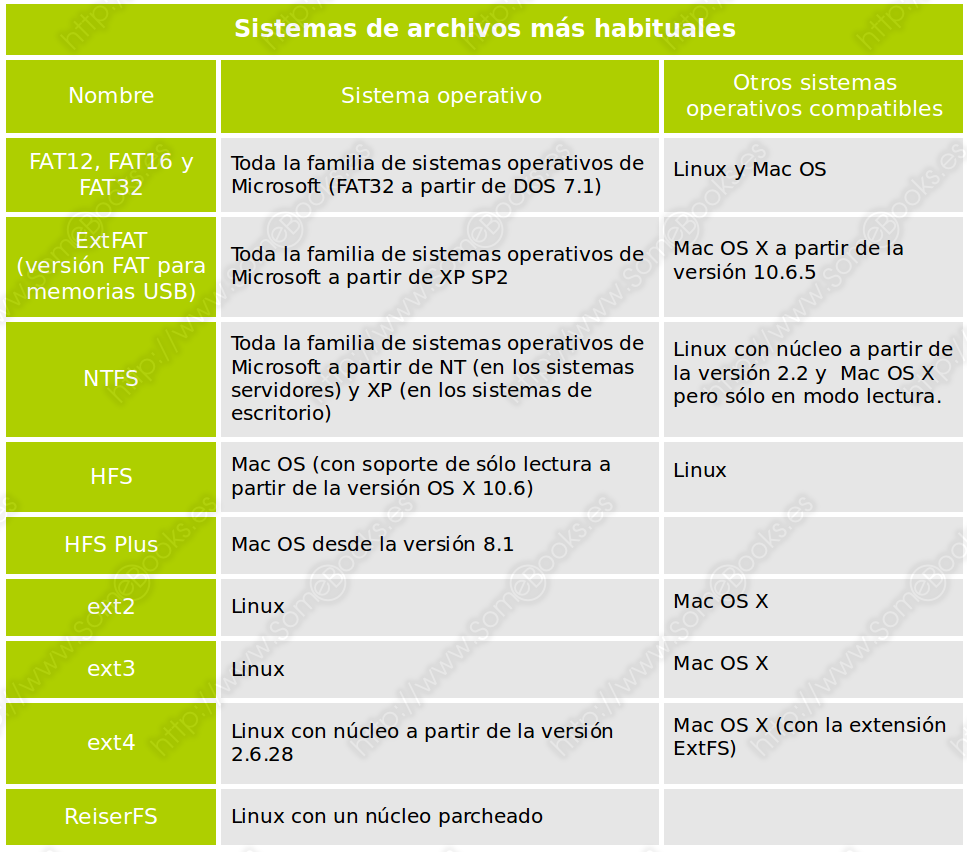
A pesar de todo, como podemos ver en la tabla anterior, existe cierto nivel de compatibilidad entre los diferentes sistemas operativos en cuanto a los sistemas de archivos, bien directamente (los incluidos en la tabla), bien a través de herramientas complementarias.
Es muy frecuente que los datos se almacenen en un dispositivo de bloque. En esos casos, un archivo no será más que un conjunto de sectores de disco. Estos sectores no se leerán o escribirán de forma individual, sino que lo harán en grupos llamados clústers.
Por lo tanto, un sistema de archivos se encargará de aspectos como …
-
Organizar de forma lógica los sectores del dispositivo para constituir archivos y directorios
-
Asignar espacio de almacenamiento a los archivos y mantener el control sobre los sectores que pertenecen a cada archivo.
-
Puedes consultar la clasificación de los dispositivos de entrada/salida en el capítulo 1.
Ofrecer los mecanismos que permitan crear nuevos archivos, cambiarles el nombre y/o la ubicación, modificar su contenido o eliminarlos.
-
Mantener la estructura jerárquica del sistema de directorios.
-
Controlar el acceso seguro a los archivos. Es decir, que sólo puedan acceder a los datos los usuarios autorizados
-
Controlar qué sectores permanecen disponibles para ser ocupados en cualquier momento.
El sistema de archivos también suele tratar como archivos los datos que se generan de forma dinámica, como los que proceden de una línea de comunicación.
Atributos y permisos
El sistema operativo debe tener la capacidad de controlar qué usuario puede acceder a cada uno de sus recursos (directorios, impresoras, conexiones de red, etc.). Para lograrlo, cada uno de estos recursos suele tener asociada una Lista de Control de Acceso o ACL (del inglés, Access Control List), en la que se relacionan los diferentes usuarios que pueden acceder y bajo qué condiciones (lectura, escritura, ejecución, …)
Por otro lado, un determinado archivo puede tener asociados diferentes atributos, que informan sobre ciertas características del archivo o del modo en el que el sistema operativo debe tratarlo. Así, un archivo puede tener atributos como: directorio, oculto, de sistema, cifrado, etc.
Organización del sistema de archivos: Nombres y rutas
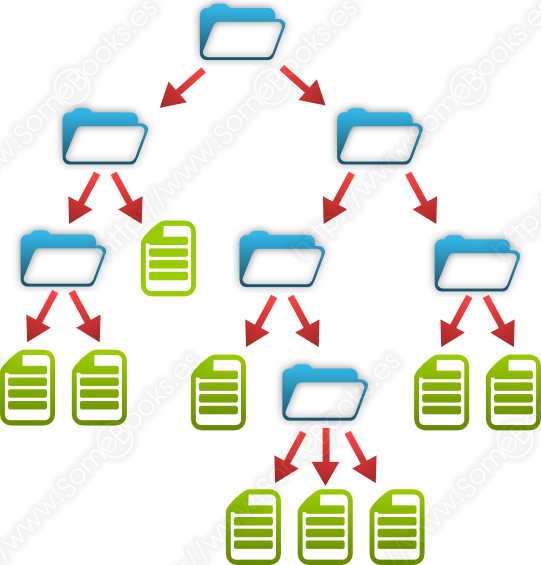
A día de hoy, prácticamente todos los sistemas de archivos que podemos encontrar organizan los archivos de forma jerárquica, permitiendo la creación de un árbol de directorios que facilitan la organización y clasificación de su contenido.
Además, para evitar ambigüedades, los sistemas operativos no permiten que, dentro del mismo directorio, existan dos archivos con el mismo nombre.
Es frecuente que la parte final del nombre termine en un punto, seguido de tres o cuatro caracteres que indican el tipo de contenido del archivo. De esta forma, el usuario sabe la clase de información que puede encontrar en su interior. Este grupo de caracteres recibe el nombre de extensión.
En la siguiente tabla incluimos algunos ejemplos:
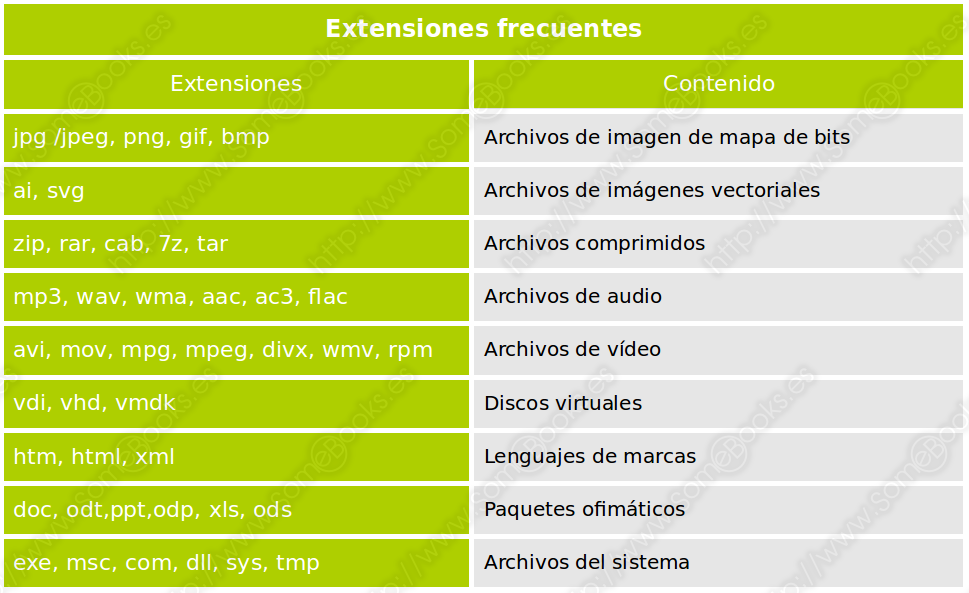
Algunos sistemas de archivos, como las diferentes versiones de FAT o incluso NTFS, utilizan las extensiones de los archivos para establecer el tipo de programa que puede interpretar la información que contienen. En otros, como GNU/Linux, se utilizan los metadatos de los archivos para identificar el tipo de información que almacenan.
Por otro lado, para expresar la ubicación exacta de un archivo o un directorio se utiliza su ruta (en inglés, path). Aunque la forma de expresar una ruta puede cambiar según el sistema operativo que estemos usando. En general se forman indicando la lista jerárquica de directorios que representa el camino que debemos recorrer para llegar hasta un archivo o directorio. En esa relación, el último elemento será el propio archivo o directorio referenciado. Al escribir una ruta, deberemos utilizar un carácter que separe cada elemento del siguiente. Este carácter separador suele ser una barra invertida (\) en los sistemas Microsoft y una barra inclinada (/) en la familia de sistemas Unix, como es el caso de GNU/Linux.
Otros caracteres especiales que podemos utilizar en una ruta son los siguientes:
-
. (un punto): Hace referencia al directorio en el que nos encontramos (también llamado directorio actual)
-
.. (dos puntos): Hace referencia al directorio que se encuentra, jerárquicamente, justo encima del directorio en el que nos encontramos (también llamado directorio padre)
-
~ (una virgulilla): En sistemas de la familia Unix, como GNU/Linux, hace referencia al directorio personal del usuario que escribe la ruta.
Además de todo lo dicho hasta ahora, también existen dos modos diferentes de escribir rutas:
-
De forma absoluta: Una ruta de este tipo hará referencia a un archivo o directorio a partir del directorio raíz.
-
En los sistemas de la familia Unix, una ruta absoluta comienza por una barra inclinada. Por ejemplo, /home/Alicia/Documentos/informe.odt
-
En los sistemas Microsoft, es necesario comenzar la ruta absoluta con la letra de unidad a la que hace referencia, seguida de dos puntos y una barra invertida. Por ejemplo, c:\Usuarios\Alicia\Documentos\informe.odt
-
-
De forma relativa: Una ruta de este tipo hará referencia a un archivo o directorio tomando como punto de partida el directorio en el que nos encontramos. Por ejemplo: ../../Jacinto/Documentos/memoria.odt (como puede apreciarse, el ejemplo es válido en sistemas de la familia Unix, pero bastaría con cambiar el sentido de las barras para que fuese válido en sistemas Microsoft).
Las rutas que identifican recursos compartidos en una red suelen hacer uso de la nomenclatura UNC (en inglés, Universal Naming Convention), que fue definida por Microsoft y que tiene la siguiente sintaxis general: \\Servidor\RecursoCompartido\ruta\archivo
Caracteres comodín (Wildcard)
 Un carácter comodín es aquél que tiene la capacidad de representar a cualquier otro carácter o conjunto de caracteres. En el sistema operativo suelen utilizarse para sustituir parte del nombre de un archivo o de alguno de los directorios que forman su ruta. Esto nos permite hacer referencia a un archivo del que no recordamos su nombre completo o bien a un grupo de archivos que tengan en común una parte de su nombre.
Un carácter comodín es aquél que tiene la capacidad de representar a cualquier otro carácter o conjunto de caracteres. En el sistema operativo suelen utilizarse para sustituir parte del nombre de un archivo o de alguno de los directorios que forman su ruta. Esto nos permite hacer referencia a un archivo del que no recordamos su nombre completo o bien a un grupo de archivos que tengan en común una parte de su nombre.
Los dos caracteres comodín mas utilizados son:
-
El asterisco (*): Representa a cualquier combinación de caracteres. Incluso cubre la posibilidad de que no haya ningún carácter.
Para entenderlo, supongamos que en un directorio tengo los siguientes archivos: Mi_imagen.png, imagen.png, imagen1.png, imagen21.png Podría hacer referencia a todos ellos escribiendo lo siguiente: *imagen*.png
-
El signo de interrogación (?): Representa a un único carácter. Así, en el ejemplo anterior, podríamos hacer referencia sólo al último archivo escribiendo lo siguiente: imagen??.png
Otros sistemas de archivos
Existen algunos sistemas de archivos que tienen un propósito específico, y que no pueden ser catalogados ni como sistemas de archivos de disco, ni como sistemas de archivos de red. Entre ellos, podemos destacar los siguientes:
-
swap: Contiene un espacio de almacenamiento en disco destinado a apoyar el funcionamiento de la memoria virtual.
-
archfs: Se trata de un sistema de archivos, creado en el espacio del usuario (FUSE, del inglés, Filesystem in Userspace), que permite navegar por los repositorios rdiff-backup.
-
cdfs: un sistema de archivos virtual de GNU/Linux que permite acceder de forma individual a los datos o a las pistas de audio en un disco compacto.
-
udev y devfs: Son sistemas de archivos virtuales que utiliza GNU/Linux para manejar los archivos almacenados en dispositivos vinculados al directorio /dev.
-
ftpfs: Es el sistema de archivos que ofrece acceso a datos a través de ftp (File Transfer Protocol).
-
nntpfs: Es un sistema de archivos, creado en el espacio del usuario (FUSE) que permite acceder a noticias en Internet usando el protocolo NNTP (Network News Transfer Protocol).
¿Qué es FUSE?
Tradicionalmente, los sistemas de archivos en los sistemas operativos UNIX y derivados se han construido como un módulo del núcleo. De este modo, cuando un usuario (o un programa) realiza una solicitud, ésta se convierte en una llamada al sistema y se ejecuta en el sistema de archivos, usando el modo privilegiado.
Se recomienda consultar los modos de ejecución en el apartado Sistema operativo. Elementos y estructura del sistema operativo del capítulo anterior.
A partir de la versión 2.6.14 del núcleo de Linux, se incluye FUSE (Filesystem in Userspace) para dar soporte a sistemas de archivo que puedan ejecutarse en modo usuario.
FUSE es un módulo del núcleo que recibe las solicitudes de los usuarios (o programas) y los pasa a un sistema de archivos que se está ejecutando en modo usuario. Así, los usuarios pueden generar sistemas de archivo sin que sea necesario modificar el núcleo del sistema operativo. Además, se incrementa el número de sistemas de archivo a los que puede dar soporte el sistema operativo.
De hecho, este es el método que se utiliza para dar soporte a NTFS o EncFS (además de los ya mencionados archfs y nntpfs) y permite montar discos duros virtuales (por ejemplo, archivos vdi) como si fuesen físicos.
Veamos, por ejemplo, el enfoque para NTFS:
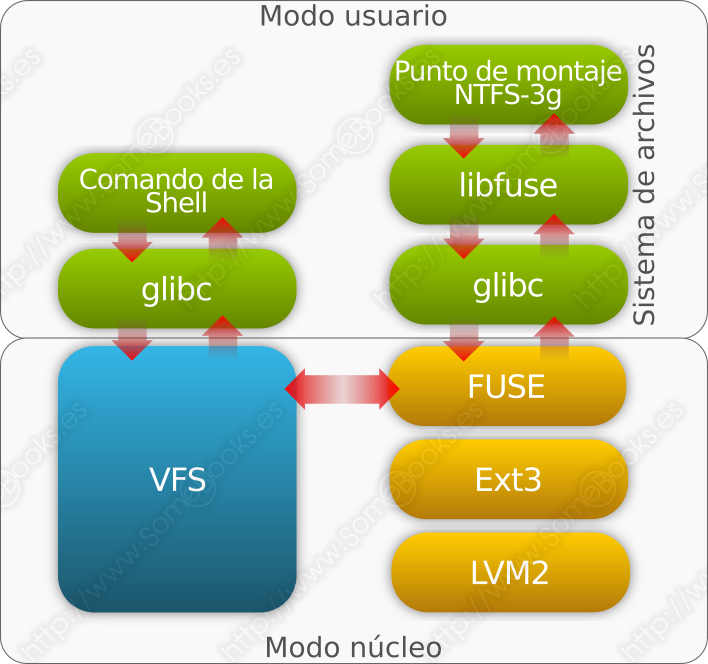
El inconveniente es que, los cambios en el modo de ejecución y la transferencia de datos penalizan el rendimiento.
Como vemos, el funcionamiento de FUSE se apoya sobre VFS (del inglés, Virtual File System), que no es más que una capa de software que actúa como intermediario entre las aplicaciones y el sistema de archivos real. De este modo, se consigue un acceso uniforme a sistemas de archivos con arquitecturas diferentes.
Tipos de sistemas de archivos y sus características
En la actualidad, los diferentes sistemas de archivos que podemos encontrar están íntimamente ligados a la familia de sistemas operativos en la que se han desarrollado. En esta afirmación, debemos considerar algunas excepciones, como el sistema de archivos FAT que, a pesar de haber nacido vinculado a la familia de sistemas Microsoft, en la actualidad es prácticamente un estándar para el intercambio de datos entre plataformas, o los sistemas de archivos para almacenamiento óptico (UDF o CDFS), que están diseñados con el mismo fin.
Por lo tanto, para estudiar los sistemas de archivos más comunes, los clasificaremos en función de la familia de sistemas operativos a la que pertenecen:
Sistemas de archivos de la familia Microsoft
A grandes rasgos, en los sistemas operativos Microsoft podemos encontrar dos tipos de sistemas de archivos totalmente diferentes:
-
 FAT (del inglés, File Allocation Table): Se trata de un sistema de archivos muy simple que acompañaba a los primeros sistemas operativos del fabricante y no tiene ninguna característica de seguridad, salvo la básica que aportan los atributos de los archivos (sólo lectura, ocultos y de sistema) y sus archivos se fragmentan con relativa facilidad.
FAT (del inglés, File Allocation Table): Se trata de un sistema de archivos muy simple que acompañaba a los primeros sistemas operativos del fabricante y no tiene ninguna característica de seguridad, salvo la básica que aportan los atributos de los archivos (sólo lectura, ocultos y de sistema) y sus archivos se fragmentan con relativa facilidad.Sus diferentes versiones acompañaron a las versiones de escritorio de los sistemas operativos Microsoft hasta Windows Me.
Las diferentes variantes, en orden cronológico son:
-
FAT12: Se implementó por primera vez en QDOS en 1980. Era capaz de direccionar un máximo de 32 MB y usaba nombres de archivo con un máximo de 8 caracteres y 3 de extensión.
-
FAT16: Se implementó sobre MS-DOS en 1984. Direccionaba hasta 90 GB usando clusters de 32 KB.
-
VFAT: Se implementó sobre Windows 3.11, que usaba el modo protegido de 32 bits de los procesadores de la época y accedía directamente al hardware y a la memoria caché, lo que aceleraba su funcionamiento.
En Windows 95 se añadió una mejora que permitía el uso de nombres largos (hasta 255 caracteres)
-
FAT32: Apareció con Windows 95 ORS2. Por diseño podría direccionar casi 8 TB, pero Microsoft lo limitó primero a 128 GB y, más adelante, con Windows XP a 32 GB.
El tamaño máximo de archivo es de 4 GB.
-
ExFat: Se presentó con Windows Embedded CE 6.0. Se trata de una mejora, adaptada a memorias USB
-
-
NTFS (del inglés, New Technology File System): Comparado con FAT, ofrece un mayor rendimiento, seguridad y fiabilidad (incluso puede recuperarse de algunos errores de disco de forma automática). Además, aplica técnicas de journaling. El único inconveniente es que sus estructuras de datos son demasiado grandes en dispositivos de almacenamiento pequeños.
Apareció con las versiones profesionales de los sistemas Microsoft (Windows NT), aunque se incorporó a las versiones de escritorio a partir de Windows XP.
Está basado en HPFS, el sistema de archivos desarrollado entre IBM y Microsoft para el sistema operativo OS/2 y permite direccionar volúmenes de hasta 16 TB (aunque puede llegar hasta los 16 EB (1 Exabyte = 1024 x 1024 TB).
Existen 5 versiones:
-
v1.0: Publicada con Windows NT 3.1 en 1993
-
v1.1: Publicada con Windows NT 3.5 en 1994
-
v1.2: Publicada con Windows NT 3.51 en 1995
-
v3.0: Publicada con Windows 2000 en 2000
-
v3.1: Publicada con Windows XP en 2001
-
Organización interna de FAT32
Para entender cómo se organiza un sistema de archivos, pondremos como ejemplo uno de los más sencillos: El sistema de archivos FAT32.
Lo primero que debemos saber es que la unidad mínima de asignación de espacio para un archivo es el clúster. Es decir, un archivo estará formado por uno o más clústers de un disco, que podrán estar en posiciones consecutivas o no consecutivas.
En principio, el número de clústers que se pueden direccionar, está en función del número de bits que se utilicen para crear las direcciones. Así, en FAT32 se utilizan 32 bits, lo que, en teoría, nos ofrecería un máximo de 232 direcciones posibles (es decir, 4.294.967.296). Sin embargo , sólo se utilizan los 28 primeros (los 4 restantes están reservados), lo que nos ofrece un máximo de 228 clústers (es decir, 268.435.456).
FAT32 puede utilizar tamaños de clúster que oscilen entre 8 y 64 sectores. Esto significa que, si el tamaño de un sector suele ser 512 bytes, un clúster podría tener entre 4.096 y 32.768 bytes. Es decir, que podríamos formatear unidades comprendidas entre 1 TiB y 8 TiB.
Como dijimos más arriba, el nombre FAT proviene del inglés File Alocation Table, y el motivo es que el almacenamiento de archivos en el disco se organiza en forma de tabla. La longitud de cada entrada (fila) de dicha tabla será de 12, 16 o 32 bits según la versión de la que estemos hablando.
La tabla FAT tendrá una entrada por cada clúster del disco que pueda contener información y su valor podrá ser alguno de los siguientes:
-
La dirección del siguiente clúster del mismo archivo.
-
Una marca de fin de archivo (EOF, del inglés End of File) que indica que es el último clúster de ese archivo.
-
Un indicativo de que el clúster está libre (en este momento no contiene información que pertenezca a ningún archivo).
-
Una marca de clúster defectuoso.
En todas las versiones del sistema de archivos FAT que han ido apareciendo, el tamaño del clúster siempre ha estado relacionado con el tamaño del dispositivo. La explicación es muy sencilla: dado que el número máximo de clústers es fijo, cuanto más grande sea el volumen, más grandes tendrán que ser los clústers.
En la siguiente imagen podemos ver una representación simplificada de cómo se organiza una tabla FAT:

Así, en el ejemplo, el archivo A estaría ocupando los clústers 2, 6, 10 y 3, en ese orden.
Es habitual que la tabla FAT se encuentre duplicada en el soporte de manera que pueda usarse la segunda copia para recuperar la primera en el caso de que ésta se hubiese corrompido.
Inconvenientes del sistema de archivos FAT
Como habrás deducido de lo que hemos dicho más arriba, en un dispositivo de 1 TiB, un archivo con un solo byte, ocupará 4096 bytes en el disco (un clúster). Y bastaría con que tuviese 4097 para que ocupase dos clústers.
Por otro lado, para que el rendimiento sea elevado, la tabla FAT suele alojarse completa en la memoria RAM, con el consiguiente desperdicio de la misma. No obstante, si se trata de ahorrar memoria almacenando sólo la parte de la FAT que se esté utilizando, cuando el archivo se encuentre muy fragmentado, el sistema necesitará realizar accesos continuos a disco para obtener porciones de la FAT que no residan en la memoria.
Sistemas de archivos de la familia Apple
A lo largo del tiempo, la familia de ordenadores del fabricante Apple han incorporado varios sistemas de archivos diferentes:

MFS (Macintosh File System): Era el sistema incluido en el Macintosh 128K (enero de 1984). Soportaba nombres de archivo con 255 caracteres (aunque sólo se podían localizar por los primeros 63).
El tamaño máximo de volumen era de 256 MB, pudiendo tener archivos del mismo tamaño
-
HFS (Hierarchical File System), también llamado Mac OS estándar: Se desarrolló para el sistema operativo Mac OS y podía usarse en discos duros, disquetes y CD-ROMs.
Su principal objetivo era aumentar el rendimiento en dispositivos de almacenamiento de mayor capacidad (hasta 2TB, con archivos de 2GB como máximo). Aunque mantiene la restricción de localizar archivos sólo por los primeros 63.
Reemplazó a MFS en septiembre de 1985.
-
HFS+ o HFS Plus, también llamado Mac OS extendido: Se introdujo en enero de 1998. Utiliza técnicas de journaling, emplea Unicode para los nombres de archivo y directorio, y es capaz de direccionar 8 EB (y admite archivos del mismo tamaño)
-
APFS (Apple File System), se anunció en junio 2016 como sustituto de HFS+. Lo soportan los sistemas operativos macOS, a partir de la versión 10.12 (Sierra), e iOS desde la versión 10.3. Su diseño está optimizado para dispositivos de memoria flash (como los discos SSD).
Sistemas de archivos de la familia GNU/Linux
Por su parte, la familia de sistemas GNU/Linux soporta una gran variedad de sistemas de archivos, aunque los más comunes son los siguientes:

ext2 (second extended filesystem): Se introdujo en enero de 1993 como una evolución de un sistema de archivos anterior, llamado ext). Admitía dispositivos de hasta 16 TB, con archivos de hasta 2 TB y nombres de 256 caracteres.
-
ext3 (third extended filesystem): Apareció en noviembre de 2001 con la versión 2.4.15 del núcleo de GNU/Linux. Mantenía su compatibilidad con ext2, pero añadía soporte para un registro por diario (journaling) y se apoyaba en un árbol binario balanceado que le otorgaba un mayor rendimiento. Admitía dispositivos con un máximo de 32 TB, con archivos que podían llegar a los 2 TB
-
ext4 (fourth extended filesystem) se publicó en octubre de 2006 con la versión 2.6.19 del núcleo de GNU/Linux y añade mejoras de velocidad y de uso de la CPU. Además, admite dispositivos de hasta 1 EB, con archivos que pueden llegar a 16 TB.
-
ReiserFS: Apareció a principios de 2001 con la versión 2.4.1 del núcleo de GNU/Linux. Fue el primer sistema de archivos soportado por el núcleo de GNU/Linux que incluía journaling.
Admitía dispositivos de hasta 16 TB, con archivos de hasta 8 TB y nombres de 256 caracteres.
-
XFS: Apareció en 1994 sobre IRIX, el Unix de la empresa Silicon Graphics Inc (actualmente SGI), pero su código fuente se liberó en mayo de 2000. Se añadió al núcleo de GNU/Linux en la versión 2.4.25, en el año 2004. Fue el primer sistema de archivos que ofreció journaling. Admite dispositivos de hasta 16 EB, con archivos que pueden llegar a 8 EB.
- ZFS: su origen se remonta a septiembre de 2004, cuando Sun Microsystems lo anunció como novedad para su sistema operativo Solaris. Su primera versión se incluyó en la publicación de OpenSolaris 27 en noviembre de 2005. Permite archivos de 16 exabytes y volúmenes que pueden llegar a los 256 x 1015 zettabytes.
Qué es un inodo
En los sistemas de archivos de la familia Unix (incluidos los sistemas operativos GNU/Linux), un inodo, o nodo-i, es la estructura de datos que se utiliza para representar cualquiera de los objetos del sistema de archivos, como archivos, directorios o enlaces simbólicos. Cada inodo contiene los atributos y la ubicación del bloque (o bloques) que almacenan la información del objeto en el disco. Dichos atributos pueden incluir metadatos (como el momento de la última modificación o acceso) e información sobre el propietario (usuario y grupo) y los permisos.
Un directorio no es más que un archivo, cuyo contenido es una lista enlazada de nombres asignados a inodos. Cada directorio contiene una entrada que lo representa a él mismo, otra para su directorio padre y una para cada uno de sus hijos. En este caso, los directorios se tratan como archivos.
Estructura de inodos en ext3
En total, en el sistema de archivos ext3, un inodo ocupa 128 bytes. Un tamaño muy conveniente, porque los bloques de almacenamiento en disco suelen ser de 4096 (4 x 210) bytes, lo que permite almacenar hasta 32 inodos en un solo bloque.
Por otro lado, las direcciones de bloque se forman con 32 bits (4 bytes), Lo que implica que se podrán direccionar, en total, 232 bloques distintos sobre el dispositivo de almacenamiento. Esto nos lleva a dispositivos con un tamaño máximo de 4 x 210 x 232 bytes, es decir, 4 x 242 bytes. Teniendo en cuenta que 1 TiB son 240 bytes, también podríamos escribir la expresión como 4 x 22 x 240 bytes, que arroja un total de 16 TiB.
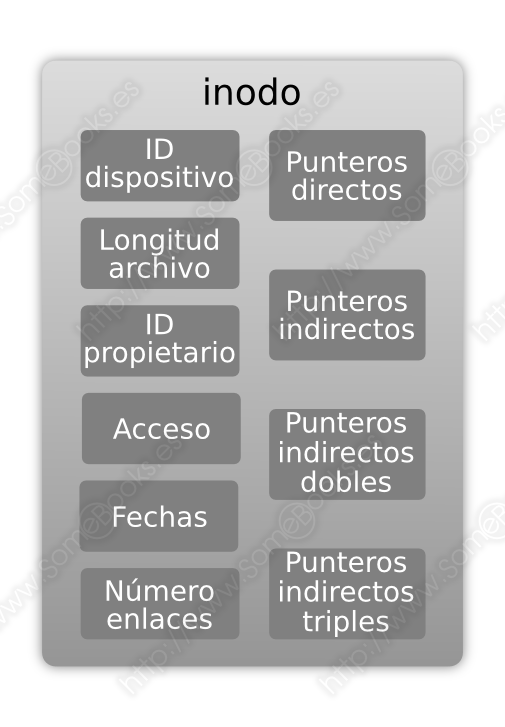
En definitiva, los inodos tienen la siguiente estructura:
-
Un identificador del dispositivo que contiene al sistema de archivos.
-
Un identificador de inodo que lo identifica dentro del sistema de archivos.
-
La longitud del archivo (en bytes).
-
El identificador del propietario del archivo
-
Acceso (lectura, escritura, ejecución) para el propietario, su grupo y otros usuarios.
-
Fechas de última modificación, último acceso, última modificación del inodo.
-
El número de enlaces simbólicos. Es decir, el número de entradas de directorio que hacen referencia a este mismo archivo. Así, el archivo sólo se borrará cuando se elimine el último enlace que le hace referencia. De lo contrario, sólo se borra la entrada de directorio y se disminuirá en uno éste valor.
-
Doce punteros con la dirección en el disco a los doce primeros bloques de datos del archivo. Se llaman punteros directos (en inglés, direct block pointers) y ocupan un total de 48 bytes (4 bytes x 12 direcciones).
-
Un puntero de indirección simple, que contiene la dirección de un bloque de punteros que, a su vez, contienen las direcciones de bloques de datos del archivo.
-
Un puntero de indirección doble, que contiene la dirección de un bloque de punteros que, a su vez, contienen la dirección de otros bloques de punteros que, finalmente, contienen las direcciones de bloques de datos del archivo.
-
Un puntero de indirección triple, que contiene la dirección de un bloque de punteros que, a su vez, contienen la dirección de otros bloques de punteros que, a su vez, contienen la dirección de otros bloques de punteros que, finalmente, contienen las direcciones de bloques de datos del archivo.
Algo similar a lo que muestra la siguiente figura:
Así pues, cuando un archivo ocupa 12 bloques o menos, sólo necesitará utilizar los punteros directos:
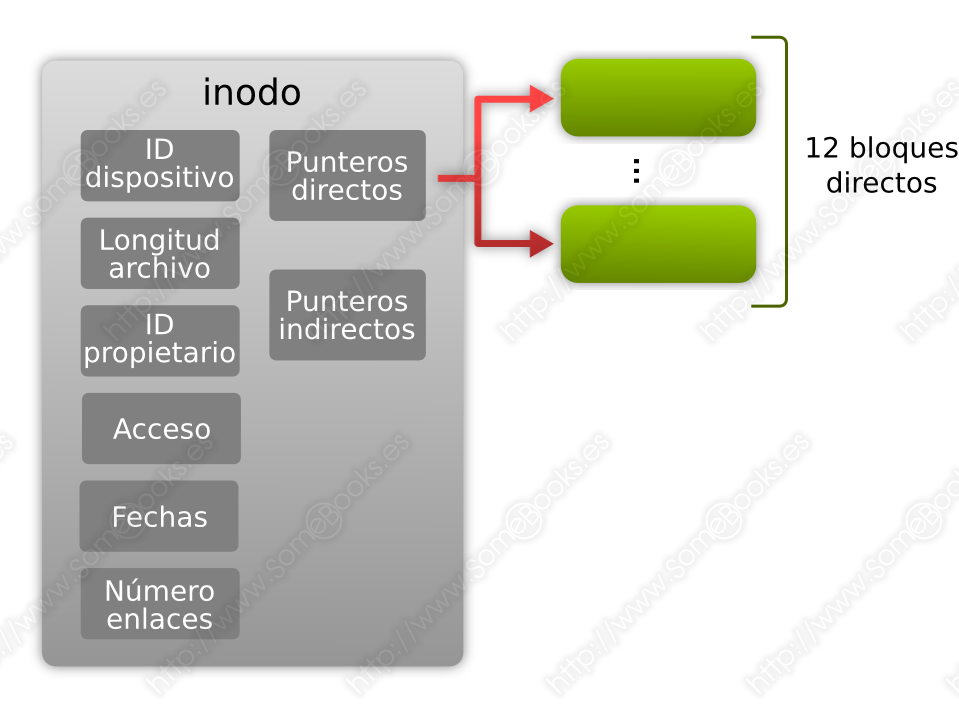
De este modo, si estuviésemos utilizando bloques de 4096 bytes, significaría que los archivos que ocupen 48 KiB (12 x 4096 bytes = 49152 bytes = 48 KiB), o menos, sólo usarían direccionamiento directo.
Para los archivos de mayor tamaño, el sistema de archivos debe recurrir, en primera instancia, a los punteros indirectos simples, que utilizan un bloque de disco (4096 bytes) para guardar las direcciones de los siguientes bloques de datos. Suponiendo que estamos trabajando con longitudes de palabra de 32 bits (4 bytes), podríamos guardar un total de 1024 direcciones de bloques (4096 / 4).
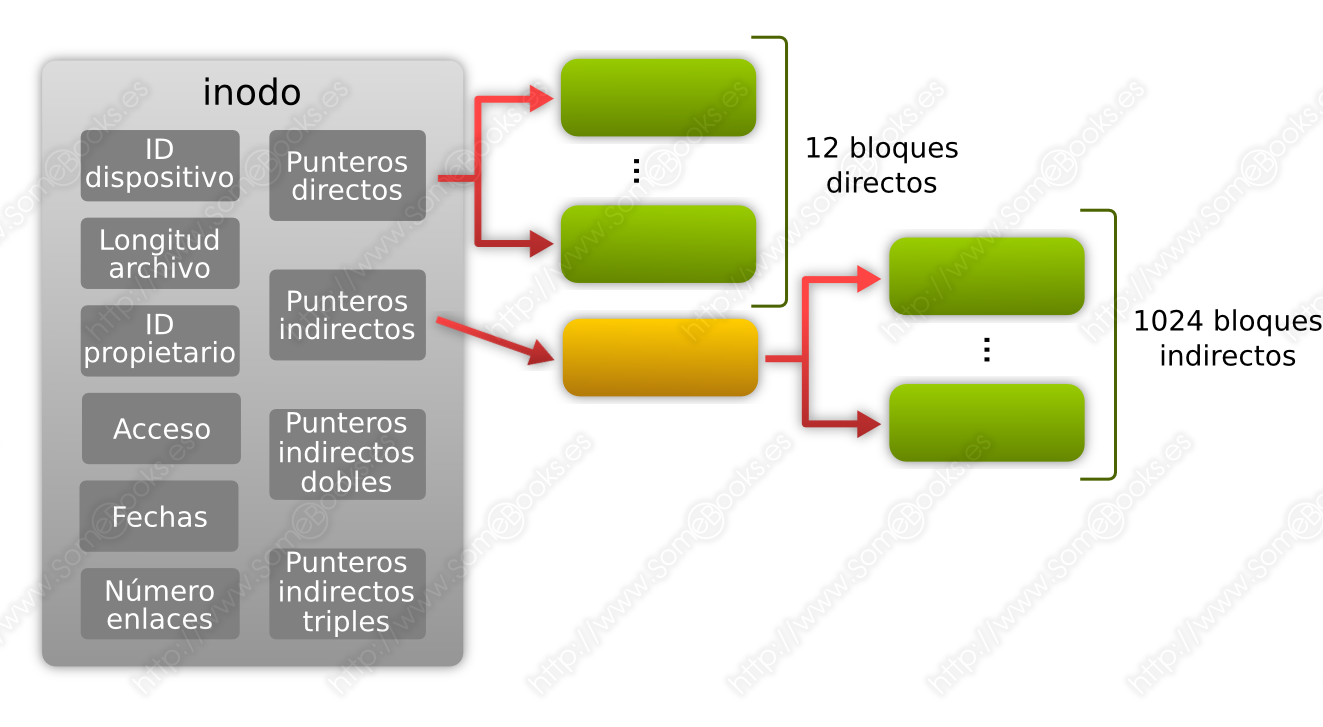
Dado que ahora podemos direccionar 1024 (210) nuevos bloques y cada uno de éstos tiene una capacidad de 4096 bytes, acabamos de obtener una capacidad máxima complementaria de 4 MiB (1024 x 4096 bytes = 4194304 bytes = 4 MiB).
Siguiendo la misma lógica, para los archivos que utilicen más de 4 MiB, el sistema de archivos recurrirá, a continuación, a los punteros indirectos dobles. En este caso, el puntero del inodo contiene la dirección de un bloque de disco donde se almacenan direcciones de bloques que, a su vez, contienen direcciones de otros bloques que son los que contienen los datos. Como ya sabemos que en cada bloque caben referencias a 1024 nuevos bloques, en este caso, la cantidad máxima de bloques de datos a los que se puede hacer referencia son 1024 x 1024 (220) = 1048576.
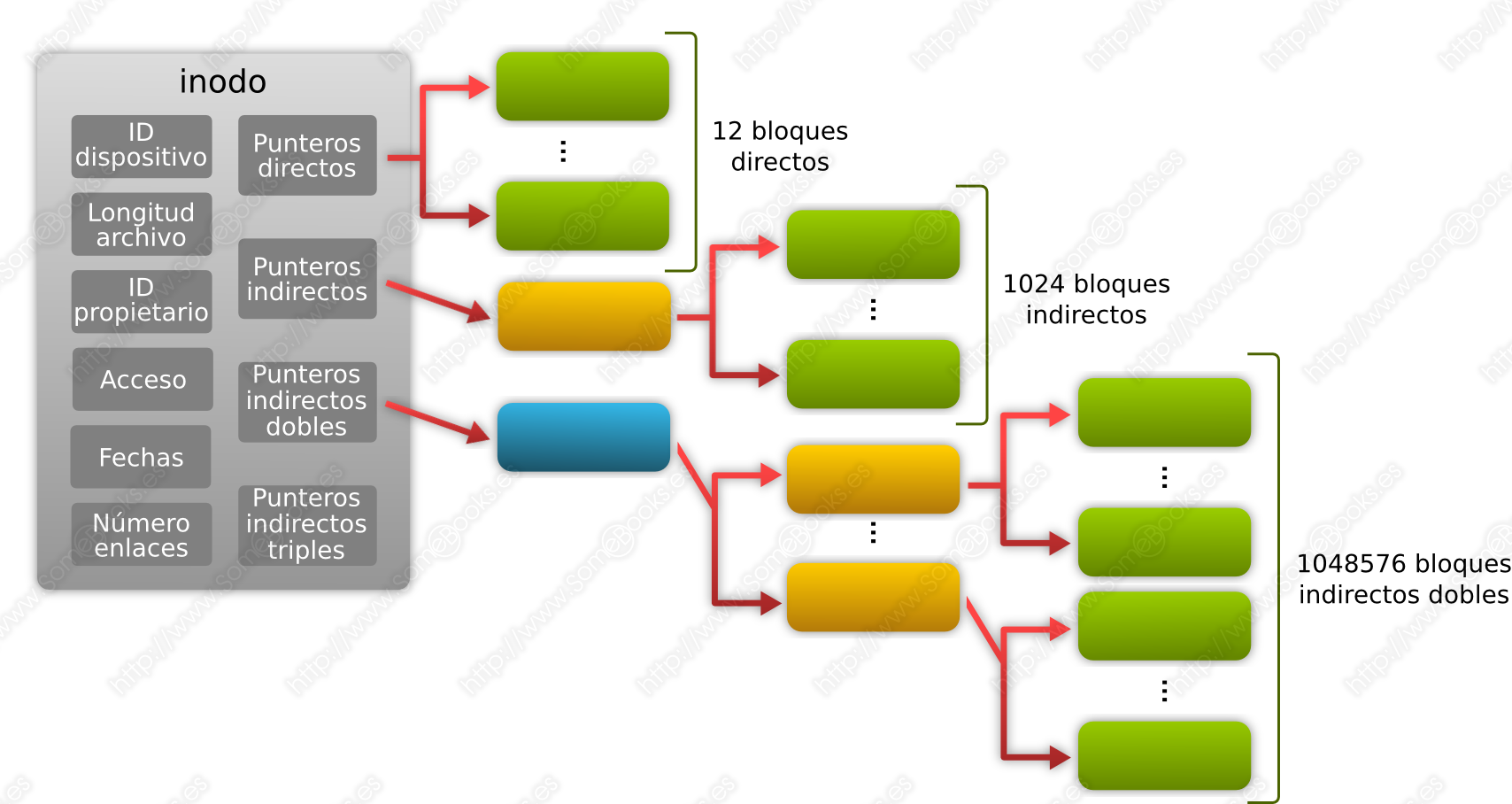
Así pues, usando punteros indirectos dobles, el sistema de archivos puede almacenar 4 GiB (1024 x 1024 x 4096 bytes = 4294967296 bytes = 4 GiB).
Como cabe esperar, siguiendo la misma lógica, los punteros indirectos triples son capaces de hacer referencia a 1073741824 bloques de datos distintos (1024 x 1024 x 1024 ó 230).
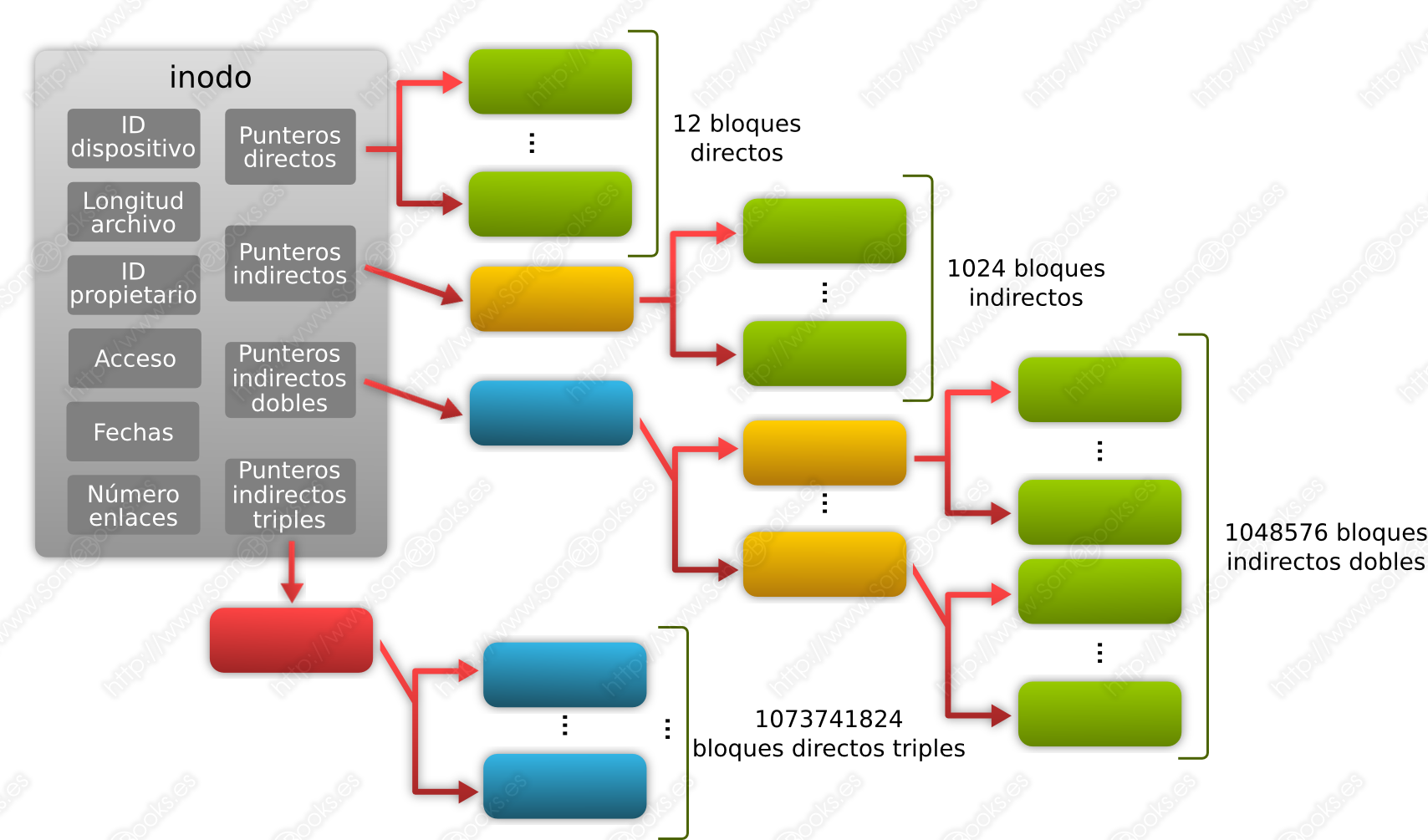
Esto significa que, usando punteros indirectos triples, el sistema de archivos puede almacenar 4 TiB de datos (1024 x 1024 x 1024 x 4096 bytes = 4398046511104 bytes = 4 TiB).
En definitiva, el tamaño máximo de un archivo en un dispositivo de almacenamiento que utilice ext3 será de 4 TiB + 4GiB + 4 MiB + 48 KiB.
Cambios para el diseño de ext4
El primer cambio significativo que se aplicó en ext4 respecto al diseño de los inodos es que el direccionamiento emplea 48 bits (en lugar de los 32 anteriores). Esto permite dar soporte a dispositivos que lleguen al 1 EiB de tamaño.
Además, en lugar de utilizar bloques indirectos, se usan extents, que son elementos formados por dos valores enteros de 48 bits. El primero de ellos indica un número de bloque inicial y el segundo la cantidad de bloques contiguos ocupados. Ahora, las 15 direcciones de bloque (60 bytes) que usaba ext3 en cada inodo (12 directas + 1 indirecta + 1 doble-indirecta + 1 triple-indirecta), se utilizan en ext4 para almacenar 4 extents y una cabecera (todas ellas de 12 bytes).

Un árbol Htree es una estructura de datos, especializada en indexación de directorios, que se mantiene balanceada
A pesar de todo, cuando un archivo está muy fragmentado, puede necesitar un número más elevado de extents. En ese caso, las extents complementarias se organizarán a modo de árbol con organización HTree. La raíz del árbol se almacena dentro de la estructura del inodo y los extents se almacenan en los nodos hoja del árbol.
Cada nodo comienza con una cabecera de extents, que contiene el número de entradas válidas para el nodo, la capacidad de las entradas que almacena el nodo, la profundidad del árbol y un número, llamado mágico, que permite diferenciar entre diferentes versiones de las extents (permitiendo añadir características nuevas en el futuro, como el incremento de direcciones de bloque a 64 bits).
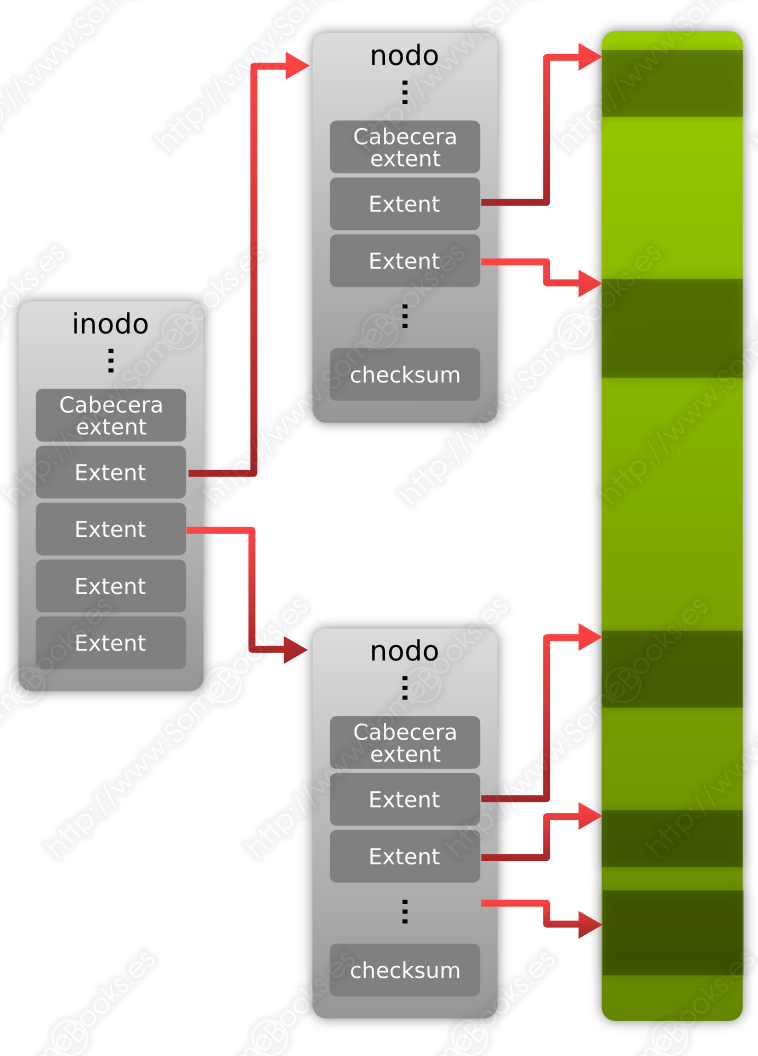
Sin embargo, ext4 trata de reducir la fragmentación al mínimo.
El sistema de archivos ZFS
![]() ZFS es un sistema de archivos que está adquiriendo relevancia en los últimos tiempos. Entre otras cosas, porque Canonical ha decidido incluirlo, de forma experimental, en Ubuntu 19.10, como un reemplazo del habitual ext4.
ZFS es un sistema de archivos que está adquiriendo relevancia en los últimos tiempos. Entre otras cosas, porque Canonical ha decidido incluirlo, de forma experimental, en Ubuntu 19.10, como un reemplazo del habitual ext4.
Como hemos dicho más arriba, su desarrollo se inició en Sun Microsystems. Sin embargo, tras la compra de Sun Microsystems por parte de Oracle, buena parte de los desarrolladores de ZFS abandonaron la compañía y crearon el proyecto OpenZFS en septiembre de 2013.
Inicialmente, su nombre provenía de Zettabyte File System aunque, posteriormente, se simplificó a Z File System.
Fundamentalmente, ZFS trata de centrarse en dos objetivos principales:
-
El soporte de grandes cantidades de información: Como hemos dicho, admite archivos de 16 exabytes y volúmenes de hasta los 256 x 1015 zettabytes.
-
Impedir que la información contenida se corrompa: Para lograrlo usa la técnica Copy-on-write, que consiste en no sobreescribir los datos actualizados. En su lugar, se utiliza un nuevo bloque de disco
Copy-on-write permite crear fácilmente instantáneas del sistema de archivos, que contendrán la versión del sistema de archivos en un momento determinado. De este modo, podrá montarse una instantánea en modo de solo lectura para recuperar la versión antigua de uno o varios archivos. Incluso podremos devolver todo el sistema al estado que tenía en una instantánea anterior y anular los cambios realizados con posterioridad.
También, se incorpora un checksum en cada archivo para detectar si se ha corrompido. En caso afirmativo, ZFS tratará de repararlo automáticamente.
Además de lo dicho hasta ahora, ZFS aún aporta dos ventajas más:
-
Administración de volúmenes: ZFS puede crear un sistema de archivos sobre un conjunto de dispositivos físicos. Pudiendo añadir más unidades a lo largo del tiempo.
-
Manejo de RAID sin software o hardware complementario: De hecho, ZFS incorpora su propia implementación de RAID, llamada RAID-Z (en realidad, una versión más fiable de RAID-5).
Transacciones. Sistemas transaccionales.
En general, cuando hablamos de transacción, nos referimos a un acuerdo entre dos partes en la que se produce un intercambio. Normalmente, una transacción estará formada por varias acciones individuales, que será necesario completar en su conjunto para que la transacción completa pueda darse por terminada.

Por ejemplo, si queremos comprar pan, deberemos realizar las siguientes acciones individuales:
-
Consultar el precio
-
Comprobar si llevamos dinero suficientemente
-
Pedir la pieza de pan al vendedor
-
Recibir la pieza de pan
-
Entregar el dinero correspondiente
Como es lógico, si la transacción se interrumpe antes de completarse satisfactoriamente, debe anularse en su totalidad.
El journaling, o registro diario, es el modo de implementar transacciones en un sistema de archivos. Se basa en crear un registro de diario (en inglés, journal) donde se anotan los datos necesarios para deshacer las modificaciones que se hayan hecho durante la transacción por si ésta fallase.
Aplicando journaling, se evita la corrupción del sistema de archivos ante cortes en la alimentación eléctrica o cualquier otro fallo inesperado. Cuando el sistema arranque después de una de estas situaciones, sólo tendrá que deshacer las transacciones inacabadas para volver a disponer de un sistema de archivos íntegro.
Administración de los sistemas de archivos
Los sistemas operativos modernos suelen realizar la mayor parte de la gestión del sistema de archivos de forma automática y transparente, tanto al usuario como al administrador. Sin embargo, existen diferentes tareas de configuración de los dispositivos de almacenamiento que estaremos obligados a realizar, tanto si hacemos funciones de usuario como si somos los administradores.
Por ejemplo, podemos aplicar algunas acciones de las que ya hemos explicamos en los siguientes artículos de SomeBooks.es:
