Capítulo 4: Estructura del sistema operativo (Parte 1)

Gestión de memoria principal
Podemos entender la memoria principal como un inmenso casillero, que almacena programas y datos. Cada una de las casillas está numerada (con una dirección).
Una palabra es el conjunto de bits que la arquitectura de un ordenador puede manejar como un todo. Los tamaños de palabra más comunes son de 16, 32 ó 64 bits.
Como dijimos al hablar de procesos, para que un programa pueda ejecutarse, sus instrucciones y sus datos tendrán que estar presentes en la memoria principal del sistema, lo que conocemos como memoria RAM. Como hemos visto más arriba, planificando el uso del procesador, mejoraremos el rendimiento general del sistema, pero esto implicará la necesidad de compartir la memoria principal entre varios procesos de forma simultánea. Por lo tanto, una buena administración de la memoria, repercutirá de forma inmediata en el comportamiento de todo el sistema informático.
El gestor de memoria deberá asignar la porción necesaria de memoria principal a cada proceso que lo necesite.
Como ya dijimos, para ejecutar una instrucción, habría que leerla desde la memoria a un registro del procesador y decodificarla (averiguar qué significa). A continuación, es posible que el sistema deba volver a la memoria para obtener los datos implicados en la operación. Finalmente, es común que los resultados obtenidos también haya que guardarlos en la memoria. Por todo ello, si la gestión de la memoria no es adecuada, el rendimiento general del sistema se verá inmediatamente disminuido.
Los sistemas operativos modernos son, casi siempre, multiprogramados. Es decir, ejecutan varios procesos de forma concurrente. Esto significa que la memoria debe dividirse para darles cabida.
Cuanto más eficaz sea ese reparto, más procesos podrán ejecutarse a la vez, lo que redundará en un mayor rendimiento (no debemos olvidar que el procesador es el elemento más rápido del sistema y que el objetivo principal consiste en que siempre tenga instrucciones listas para ser ejecutadas).
Además, la gestión de memoria deberá cumplir con las siguientes necesidades:
-
Protección: Debe evitarse que un proceso haga referencia a posiciones de memoria de un proceso diferente.
Como el sistema operativo no puede anticiparse a todos los accesos que realizará un proceso durante su ejecución, es el procesador quien debe tener un mecanismo que intercepte los accesos no permitidos.
-
Reubicación: Como veremos más adelante, una forma de dar cabida a más procesos consiste en descargar a disco la totalidad o una parte de la memoria ocupada por un proceso (por ejemplo, mientras se encuentra bloqueado). La reubicación consiste en que al volver a la memoria, no sea necesario que ocupe la posición original.
Para que esto sea posible las referencias que hagan los programas a direcciones de memoria deben ser lógicas y serán el hardware y el sistema operativo quienes colaboren para realizar la traducción.
-
Compartición: Debe existir la posibilidad de que varios procesos compartan información a través de una zona de memoria compartida. Por ejemplo, es más eficiente que varios procesos accedan al mismo código de una biblioteca de funciones compartida (lo que en Windows conocemos como DLL), que mantener varias copias de ésta.
Igual puede ocurrir con datos que manejen diferentes procesos.
Sin embargo, para tratar de comprender la complejidad de la gestión de memoria, estudiaremos distintos mecanismos, de más sencillo a más complejo, pudiendo entender la explicación como una evolución.
Gestión de memoria para un solo proceso
En los primeros ordenadores, la memoria principal se dividía en dos partes: una para la parte del sistema operativo que debía estar siempre en memoria (que recibía el nombre de monitor) y otra para un único proceso de usuario. Un ejemplo de este esquema lo representan las primeras versiones del sistema operativo MS-DOS, aunque, en su caso, la parte superior del espacio de direcciones lo ocupaba el software de la BIOS.
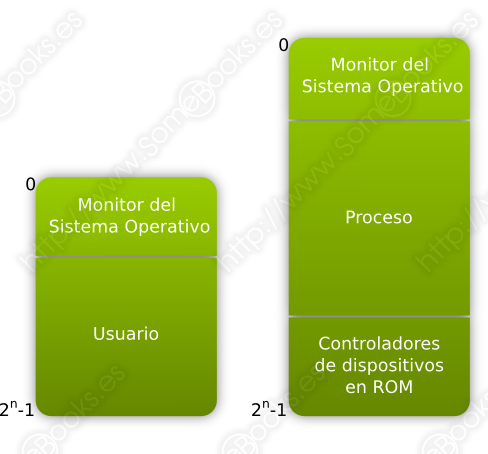
Lógicamente, sólo podía ejecutarse un proceso cada vez y, cuando éste terminaba, el control volvía al sistema operativo.
Gestión de memoria con particiones fijas
El administrador (o incluso un operador) divide la memoria en fragmentos antes del inicio de la ejecución de los programas. Cuando llega un nuevo proceso, el planificador lo ubica en la partición con el tamaño más adecuado y, cuando un proceso acaba, su partición queda libre para un nuevo uso.
Este método recibe también el nombre de Multiprogramación con un número fijo de tareas, o MFT (del inglés, Multitasking with a Fixed number of Tasks).
Era frecuente organizar la carga de trabajo según las particiones de memoria, creando una lista para cada una de ellas en función de su tamaño.
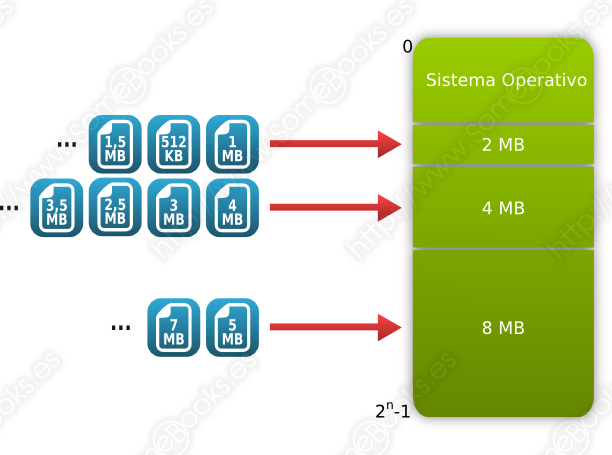
Otra opción es disponer de una cola única y elegir las tareas que se adapten a las particiones que quedan libres, aunque esto discrimina a las tareas con menos requisitos, porque tienden a desperdiciar espacio.
En este tipo de esquema surge el concepto de intercambio (en inglés, swapping), que consiste, básicamente en mover a memoria secundaria (normalmente disco), los procesos que se encuentran bloqueados en espera de un suceso. De esta forma, se puede dar cabida a nuevos procesos.
El módulo del sistema operativo que se encarga del intercambio se llama, precisamente, intercambiador y se encarga de elegir los procesos que deben moverse de memoria principal a secundaria y a la inversa. También administra el espacio reservado en la memoria secundaria para estos fines.
Relacionado con el concepto de intercambio se encuentra el concepto de reubicación que consiste, básicamente, en que un determinado proceso puede ejecutarse en diferentes particiones de memoria, no sólo en sucesivas ejecuciones, sino incluso durante la misma ejecución. De esta forma, cuando un programa haga referencia a una posición de memoria x, en realidad estará refiriéndose a una posición relativa al comienzo de la partición. Es decir, si la partición comienza en la dirección y, la posición exacta a la que hace referencia el programa sería la y + x.
Por consiguiente, podremos hablar de dos tipos de direcciones de memoria:
-
La dirección lógica o virtual, que es la dirección a la que hace referencia el programa (en la explicación anterior, la dirección x)
-
La dirección física, que es la dirección real a la que se accede (en la explicación anterior, la dirección y + x).
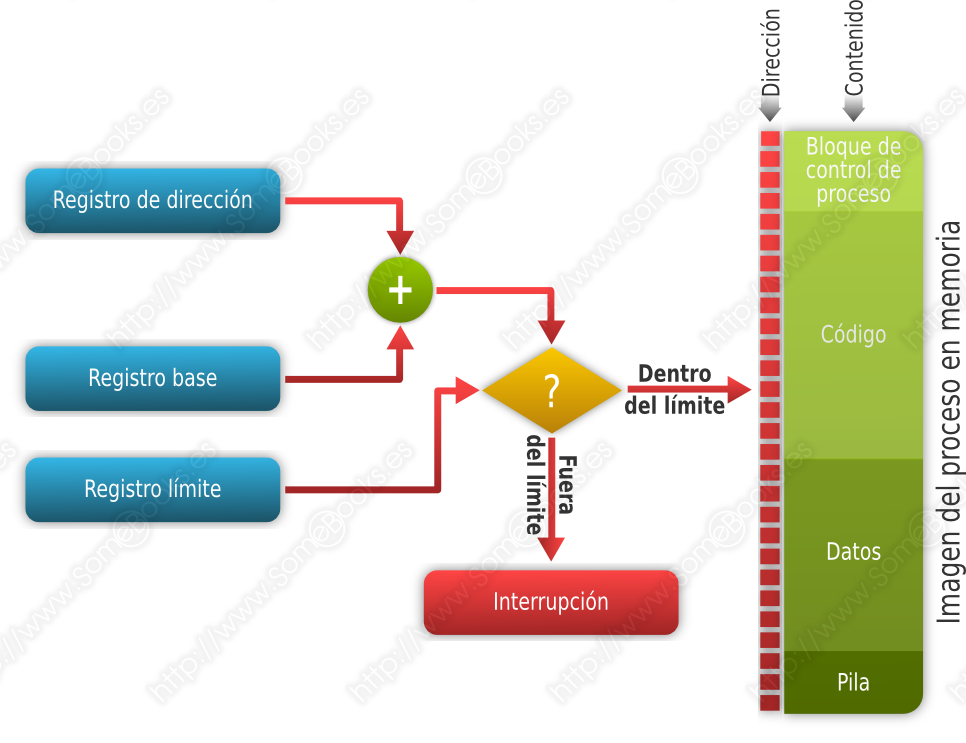
Para realizar estos cálculos a gran velocidad, el procesador dispondrá de un registro base que contiene la dirección de inicio de la partición que ocupa el proceso.
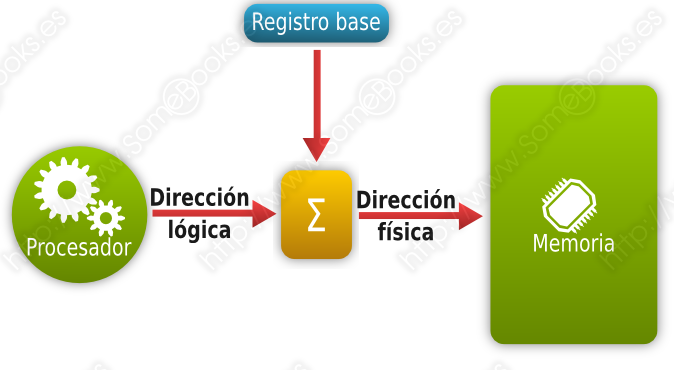
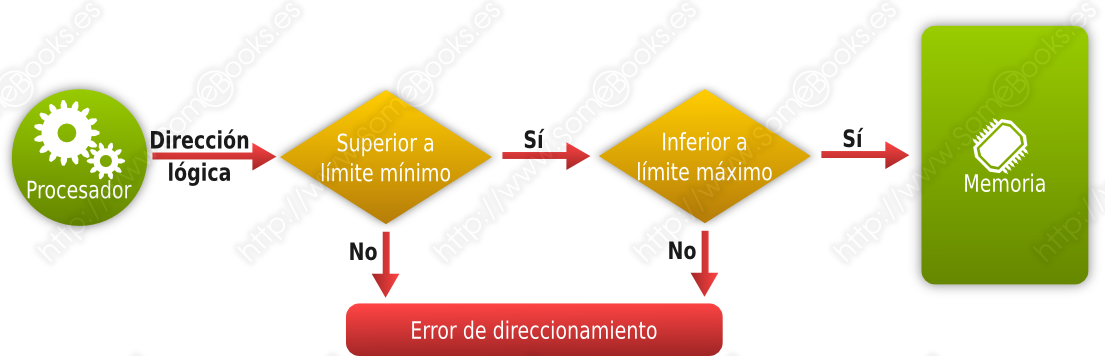
Además, es necesario establecer un mecanismo de protección para evitar que un proceso, por error o de forma intencionada, pueda acceder a posiciones de memoria que se encuentren más allá del espacio que tenga asignado. Para lograrlo, se implementa un registro límite que contiene la longitud de la partición que se está utilizando. De esta forma, las referencias de cada proceso se calculan añadiendo al registro base la dirección lógica y comprobando que no se excede el registro límite.
La dificultad en este esquema de memoria es obtener el equilibrio entre el tamaño de las particiones y el de los procesos que deben ubicarse en ellas. En este sentido, podemos encontrarnos con dos formas diferentes de desaprovechamiento:
-
Fragmentación interna: Ocurre cuando existen particiones grandes y la mayoría de los procesos no las ocuparán enteras. Es decir, el derroche de memoria se produce dentro de la asignación al proceso.
-
Fragmentación externa: Ocurre cuando hay particiones excesivamente pequeñas y es difícil encontrar procesos que quepan dentro. Es decir, el derroche se produce entre la memoria que no está asignada a ningún proceso.
Un ejemplo de este esquema lo representan los grandes ordenadores de IBM que incorporaban el sistema operativo OS/360.
La Gestión de memoria con particiones fijas tiene las ventajas de una implementación sencilla y que necesita poco software por parte del sistema operativo. Además, ofrece poca sobrecarga de procesamiento.
Sin embargo, el número de procesos que pueden estar activos es limitado. El resto deben encontrase Suspendidos (descargados a memoria secundaria). Además, los procesos más pequeños tienden a desperdiciar gran parte del tamaño de las particiones.
Gestión de memoria con particiones variables
Se basa en la idea de que las particiones de memoria vayan cambiando de tamaño a lo largo del tiempo. El sistema dispondrá de una tabla donde se representen las zonas de memoria que se encuentran ocupadas.
Cuando llega un proceso, se busca un bloque de memoria suficientemente grande para contenerlo y se le asigna sólo la porción necesaria. El resto del bloque queda libre para otra asignación. Cuando un proceso termina, la memoria que ocupaba queda disponible y, si se encuentra junto a otro bloque libre, se une a él.
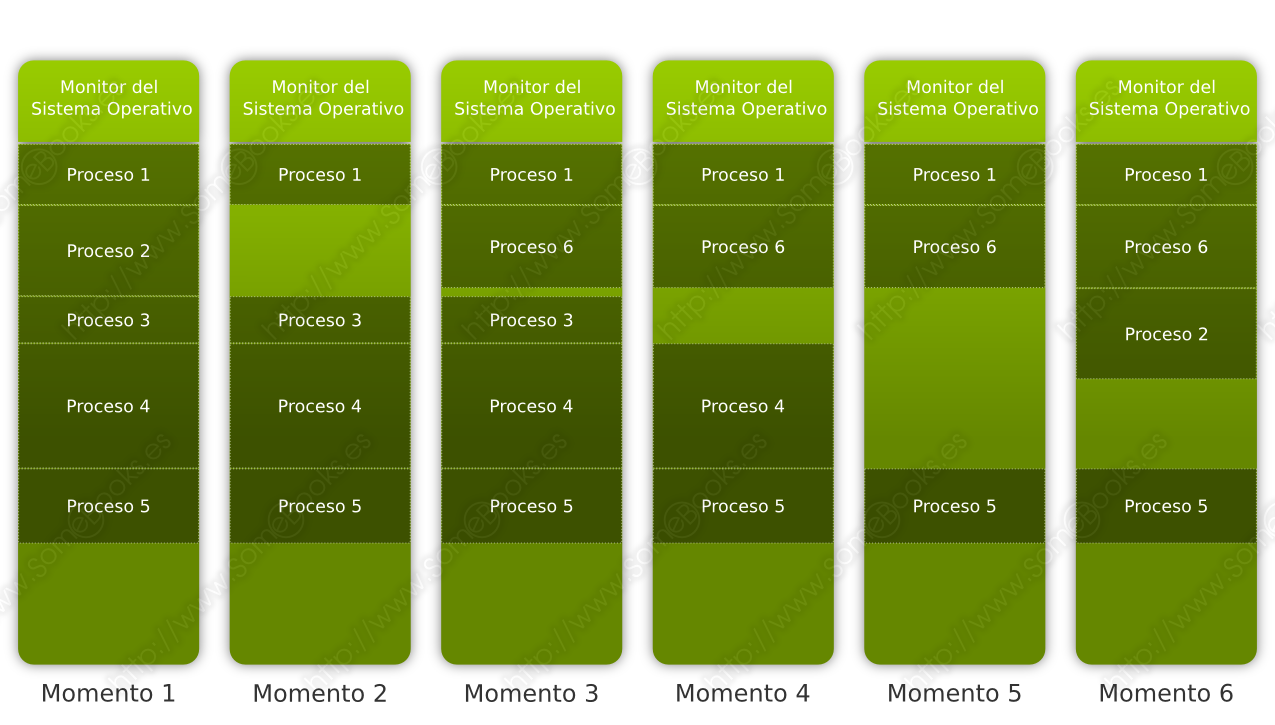
En cualquier caso, el problema de esta idea es que, si hay múltiples asignaciones y liberaciones de memoria, ésta tenderá a tener una gran fragmentación externa.
Sin embargo, el problema se resuelve aplicando, cuando sea necesario, un procedimiento de compactación de memoria, que consiste en desplazar los bloques asignados hacia un extremo y uniendo a su vez todos los bloques libres en uno más grande. Lógicamente, el tiempo que debe emplearse para realizar esta tarea es su gran inconveniente.
En cuanto a la asignación, debe estar destinada a retrasar el momento en que sea necesaria la compactación de memoria. Existen diferentes opciones a la hora de elegir el bloque más adecuado para un proceso:
-
El primer ajuste: Se asigna el proceso al primer bloque libre en el que quepa. Con el tiempo, los espacios disponibles del principio de la memoria tenderán a ser pequeños y difíciles de utilizar.
Es bastante rápido, aunque necesita recorrer los primeros bloques hasta encontrar un hueco disponible.
-
El siguiente ajuste: Busca un hueco a partir de la última asignación. Es frecuente que se reserve espacio en el bloque que queda disponible al final de la memoria, que se divide en pequeñas porciones.
Lo normal es que requiera frecuentes compactaciones de memoria para obtener un bloque grande al final de la memoria.
-
El mejor ajuste: Se asigna el bloque más pequeño cuya capacidad sea suficiente para contener al proceso. El resultado es peor que el anterior, porque los fragmentos resultantes son más pequeños y, por lo tanto, difíciles de utilizar.
Lo normal es que requiera frecuentes compactaciones de memoria.
-
El peor ajuste: Se asignan primero los fragmentos de memoria más grandes, esperando que los restos obtenidos puedan ser más sencillos de utilizar. Suele requerir compactaciones de memoria más tardías, aunque necesita recorrer todos los bloques libres antes de elegir cada destino.
Usando las particiones variables, se pueden seguir aplicando técnicas de intercambio, para mover a memoria secundaria, los procesos que se encuentran bloqueados en espera de un suceso.
Reubicación
Según lo que acabamos de decir, cada vez que un proceso (o una parte de este), se descargue a memoria secundaria (o cada vez que se compacte la memoria), al volver a ejecutarse, podrán haber cambiado las direcciones físicas donde se encontraba. Este mecanismo recibe el nombre de Reubicación.
Para lograr que la Reubicación funcione, el proceso de traducción de direcciones virtuales a direcciones físicas necesitará de la participación de dos registros en el procesador:
-
Registro base: Que contiene la dirección en memoria principal del proceso.
-
Registro límite: Que contiene la última posición a la que puede hacer referencia el proceso.
Si cuando sumamos la dirección relativa al registro base obtenemos un resultado inferior a dicho registro base o superior al registro límite, el procesador genera una interrupción que deberá ser procesada por el sistema operativo.
Paginación
En la Gestión de memoria con particiones variables, hemos visto que la memoria disponible tiende a no estar en posiciones contiguas, por lo que se produce una considerable fragmentación externa (la memoria disponible se dispersa a lo largo del espacio de direcciones.
Para resolver esta circunstancia, se planteó la posibilidad de que el espacio de memoria que usa un determinado proceso no tuviese que estar en posiciones contiguas. Así, en un esquema de paginación, la memoria se divide en trozos del mismo tamaño que reciben el nombre de marcos de página (o, en inglés, frames). Del mismo modo, los procesos se dividen en fragmentos del mismo tamaño denominados páginas.
A modo de ejemplo, imagina que el proceso que queremos cargar en memoria lo representáramos con el zumo contenido en la botella de la siguiente imagen. Por su parte, la memoria donde pretendemos almacenarlo estaría representada por los vasos. Cada vaso, sería el equivalente a un marco de página de la memoria.

Así, cuando carguemos el proceso en memoria, cada página (cantidad de zumo del tamaño de un vaso) se ubicará en un marco de página diferente.

De este modo, cuando llegue un nuevo proceso, el único problema será encontrar la cantidad suficiente de marcos de página disponibles en la memoria principal.
Gracias a este planteamiento, se acaba con la fragmentación externa, y la fragmentación interna quedará reducida al último marco de página asignado a cada proceso. Lo que equivaldría, en nuestro ejemplo, al último vaso.
Cabe esperar que, por término medio, la mitad del último marco de página quede desocupado.
Como podrás suponer, este esquema necesita un método que traduzca las direcciones virtuales a direcciones físicas, teniendo en cuenta la ubicación real de cada marco de página. Este método se basa en la creación de una tabla de páginas, para cada proceso, en el momento de cargarlo en memoria. En ella se establecerá el paralelismo entre cada página y su marco de página correspondiente.
Por lo tanto, las direcciones virtuales constarán de un número de página y un desplazamiento dentro de ella. El número de página actuará como índice en la tabla de páginas.
Además, es frecuente que el sistema operativo mantenga una lista de marcos de página disponibles.
Las direcciones virtuales también suelen llamarse direcciones relativas y suelen asignarse durante la compilación del programa, siendo relativas al comienzo del mismo (que será la dirección 0 de la página 0).
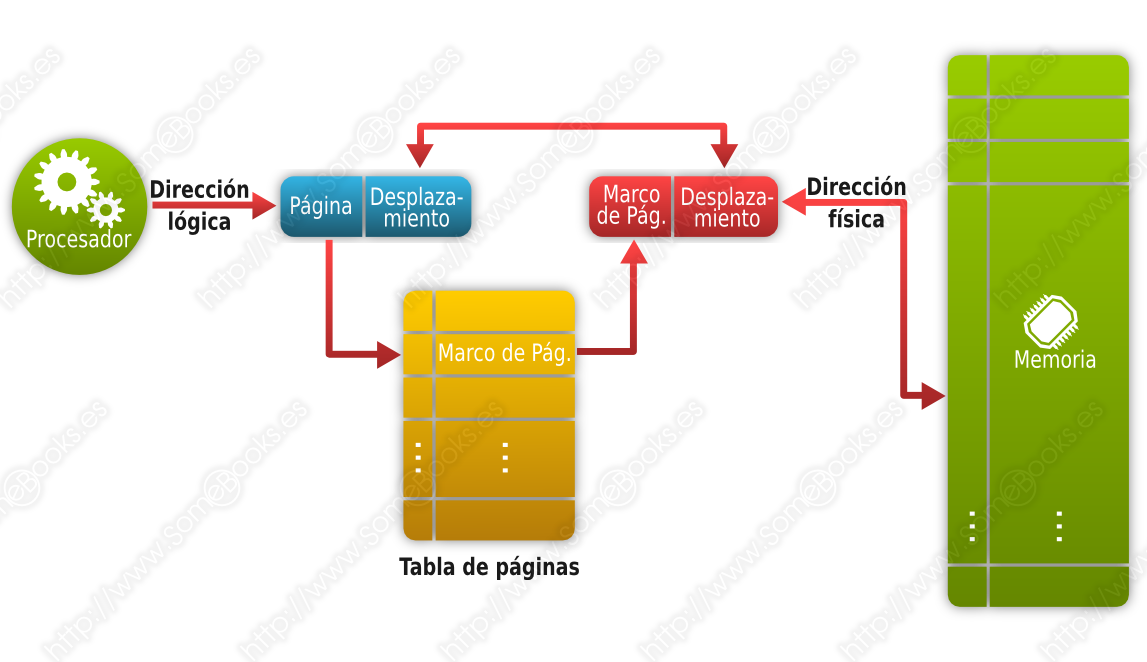
Dado que este método implica constantes traducciones de direcciones virtuales a direcciones físicas, para evitar que el sistema sufra una importante penalización de rendimiento, habrá que recurrir a un hardware específico para la traducción.
Por otra parte, el sistema operativo dispondrá de un mapa de la memoria, con una entrada por cada marco de página, donde se indique cuáles están libres y cuáles ocupados.
Ejemplo de paginación
Un ejemplo del funcionamiento de este método lo encontramos en el microprocesador Intel 8088 de los primeros ordenadores personales, aunque Intel utiliza el nombre segmento para referirse al concepto de página.
En el Intel 8088, los registros del procesador eran de 16 bits. Esto significaba que el registro de direcciones podía referenciar 216 (65,536) posiciones de memoria diferentes. Es decir, 64 KB.
Expresado en hexadecimal, los valores de direcciones válidos estarían entre 0000(16 y FFFF(16.
Sin embargo, el bus de direcciones en aquellos ordenadores era de 20 bits, lo que nos permitiría un máximo de 220 (1,048,576) direcciones de memoria diferentes, que podrían expresarse con valores comprendidos entre 00000(16 y FFFFF(16.
Para conseguir aprovechar toda la capacidad del bus, las direcciones lógicas se representaron con dos valores de 16 bits: El de la izquierda representaba el desplazamiento y el de la derecha la página (o segmento en terminología Intel).
Por ejemplo, una dirección lógica válida sería: 1B3C:A23E
Para calcular la dirección física se realiza una operación llamada suma con desplazamiento, que consiste en añadirle un 0 al valor del desplazamiento (esto equivale a multiplicarlo por 16). A continuación, se le suma el valor de la página.
Para nuestro ejemplo, la operación sería 1B3C0(16 + A23E(16 = 255FE(16.
Por lo tanto, la dirección física sería 255FE.
Como hemos dicho al principio, los procesadores Intel 8088 disponían de registros, de 16 bits, donde guardar los valores de desplazamiento. Es decir, las direcciones dentro de una página. Además, tenían 4 registros, también de 16 bits, para identificar las páginas, que guardaban la dirección de la página activa en cada momento:
-
CS (Code segment), que tiene la dirección de la página con el programa que se está ejecutando.
-
DS (Data segment), con la dirección de la página de datos del programa que se está ejecutando.
-
SS (Stack segment), que tiene la dirección de la página con la pila del programa.
-
ES (Extra segment), la dirección de una página auxiliar que puede usarse como complemento a cualquiera de los anteriores o para guardar de forma temporal direcciones intermedias.
En ocasiones, si el programa es pequeño, puede usar la misma página para todas las funciones.
Un aspecto a tener en cuenta será el tamaño de los marcos de página:
-
Con marcos de página pequeños, tendremos poca fragmentación interna y tablas de páginas grandes.
-
Con marcos de página grandes, tendremos más fragmentación interna y tablas de páginas pequeñas.
Usando la paginación, se pueden seguir aplicando técnicas de intercambio, para mover a memoria secundaria, los procesos que se encuentran bloqueados en espera de un suceso.
Otras consideraciones a tener en cuenta
Cuando se utilizan tablas de páginas de gran tamaño, puede que buena parte de las tablas de los procesos activos se encuentren descargados en memoria secundaria, perjudicando su rendimiento.
Además, el diseño de la memoria secundaria suele estar orientado al manejo de bloques grandes, que se adecuan mejor al uso de páginas de mayor tamaño.
Sin embargo, si utilizamos páginas pequeñas, cuando un proceso lleve un tiempo ejecutándose, todas sus páginas de memoria tendrán referencias con una alta probabilidad de ser utilizadas, lo que reducirá la tasa de fallos de página (ver el principio de cercanía, más adelante, en el apartado Gestión de Entrada/Salida).
En cualquier caso, el tamaño de página deberá estar relacionado con la cantidad de memoria principal y el uso que vayamos a hacer de ella. Por ejemplo, las técnicas de programación orientada a objetos produce programas con bloques de código pequeños que generan referencias a posiciones de memoria dispersas en breves periodos de tiempo. Por su parte, las aplicaciones multihilo suelen modificar bruscamente el flujo de referencias a instrucciones y datos.
Segmentación
Hasta ahora, hemos visto el problema de la gestión de memoria desde el punto de vista del sistema operativo, donde la asignación de memoria se realiza en función del tamaño total de un proceso o dividiendo éste en porciones de la misma longitud. Sin embargo, los programadores y los usuarios necesitan manejar sus datos de un modo más flexible: Tanto las funciones y procedimientos en las que se dividen los programas, como las estructuras en las que se organizan los datos (como tablas o pilas), tienen tamaños diversos.
Por lo tanto, podemos decir que un programa es un conjunto de elementos lógicos de tamaños variables.
Es como si el zumo del ejemplo anterior fuese en realidad una mezcla (por ejemplo, naranja, kiwi y fresa) y nos interesara mantenerlos separados. Entonces, podríamos utilizar varios envases más pequeños. Todos juntos representarían al mismo proceso:

Para dar cobertura a este planteamiento, la segmentación plantea que en el momento de compilar un programa, éste se convierta en un conjunto de segmentos a los que se asignará un identificador, un punto de inicio y un tamaño. Las direcciones se expresarán mediante un número de segmento y un desplazamiento dentro de él, y el tamaño asegura que no se realizan referencias a direcciones ilegales dentro del segmento.
Además, como cada componente lógico del proceso se encuentra en un segmento diferente, podemos mejorar la protección haciendo que los segmentos que contienen código sean de solo lectura. También podemos asegurar que un fragmento de código no acceda al código de un fragmento diferente.
Por otra parte, al encontrarse cada bloque lógico del programa en un segmento distinto, podría compartirse código entre diferentes programas de un modo sencillo.
De forma parecida a como ocurría en la paginación, la conversión de una dirección virtual a su correspondiente dirección física se realiza utilizando una tabla de segmentos.
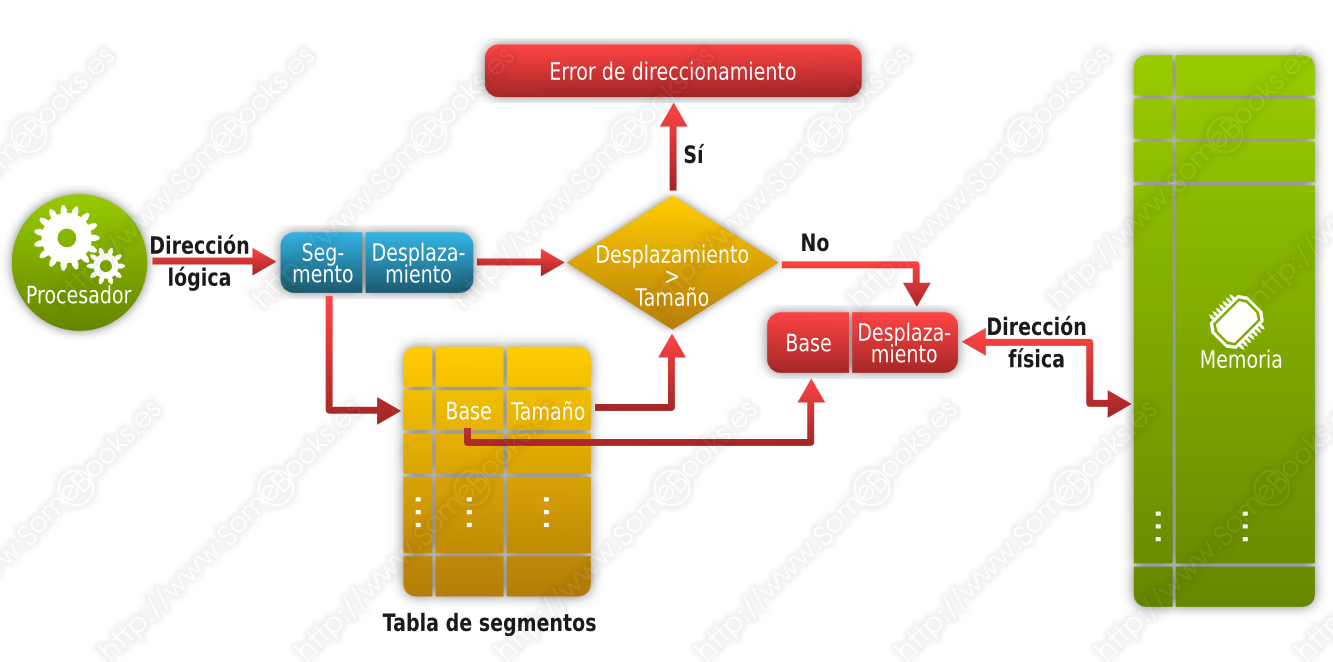
Como en el caso de la paginación, la segmentación puede extender el espacio físico de almacenamiento utilizando técnicas de intercambio.
Paginación y segmentación combinadas
Dado que la segmentación ofrece ventajas desde el punto de vista del usuario, pero la paginación simplifica la perspectiva del sistema operativo, cuando el tamaño de los segmentos es grande, es frecuente que se utilice una combinación de ambas. La idea es dividir cada segmento en páginas de longitud fija para su ubicación en memoria.
Siguiendo con nuestro ejemplo anterior, el contenido de cada botella utilizaría su propio conjunto de vasos para cargarse en memoria. Aunque no debemos olvidar que todo el zumo forma parte del mismo proceso:

Como en la segmentación pura, las direcciones se expresarán mediante un número de segmento y un desplazamiento dentro de él. Sin embargo, ahora en la entrada de la tabla de segmentos la dirección base hace referencia al inicio de la tabla de páginas asociada al segmento. El desplazamiento dentro del segmento se divide por el tamaño de página para encontrar el marco de página adecuado. El resto de la división anterior representará la dirección que estamos buscando.
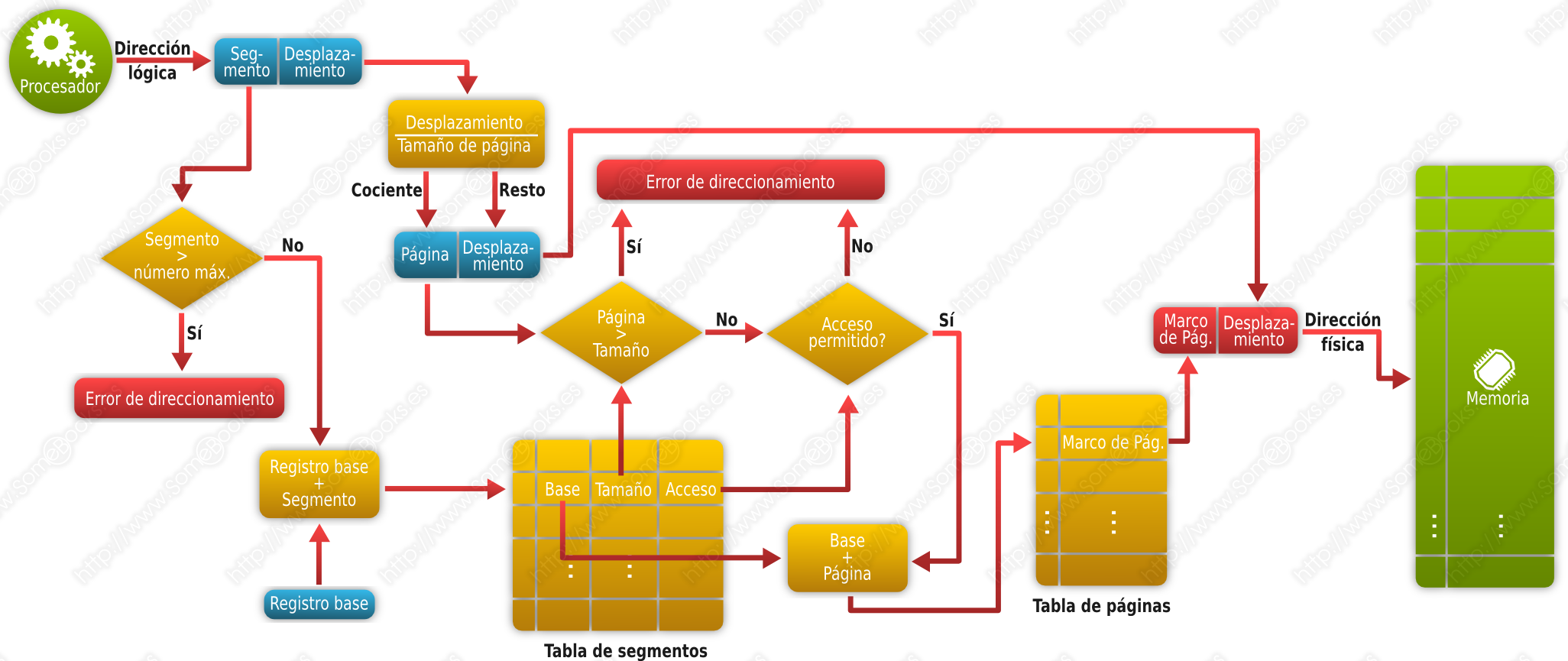
Este método ofrece una gran flexibilidad, pero tiene tres inconvenientes:
-
El proceso de traducción es más complejo, por lo que consumirá más recursos.
-
Dado que cada segmento tiene su propia tabla de páginas, el espacio destinado al almacenamiento de tablas de páginas será mucho mayor.
-
Como cada segmento tiene su propia tabla de páginas, podremos tener un marco de páginas incompleto al final de cada uno de los segmentos asignados a un proceso, lo que implica una mayor fragmentación interna.
Memoria virtual.
Todos los métodos estudiados hasta el momento suponen que un proceso debe estar completamente cargado en memoria para poder ejecutarse. Sin embargo, el modelo de Memoria virtual aplica los mecanismos de intercambio que ya hemos mencionado para que las partes de un proceso que no estén siendo utilizadas en un momento concreto, puedan residir en memoria secundaria. De esta forma, se libera una mayor cantidad de memoria principal para albergar un número de procesos superior. Además, este planteamiento nos permitiría ejecutar procesos que fuesen más grandes que la memoria física.
Normalmente se implementa a partir de los conceptos de paginación y/o segmentación que hemos estudiado antes.
Cuando el proceso hace referencia a una dirección de memoria que no reside en memoria principal, se produce un fallo de página. En ese momento, el sistema localiza un marco de página libre y carga en él la página necesaria. Si no hubiese marcos libres, habría que aplicar un algoritmo de sustitución para elegir la página de este u otro proceso que debe abandonar la memoria principal para dejar espacio a la que debe cargarse.
Mientras dura toda esta operación, el proceso que originó el fallo de página permanece en estado Bloqueado.
Para saber qué páginas se encuentran en memoria principal y cuáles están en el disco, la tabla de páginas puede incluir un bit de presencia.
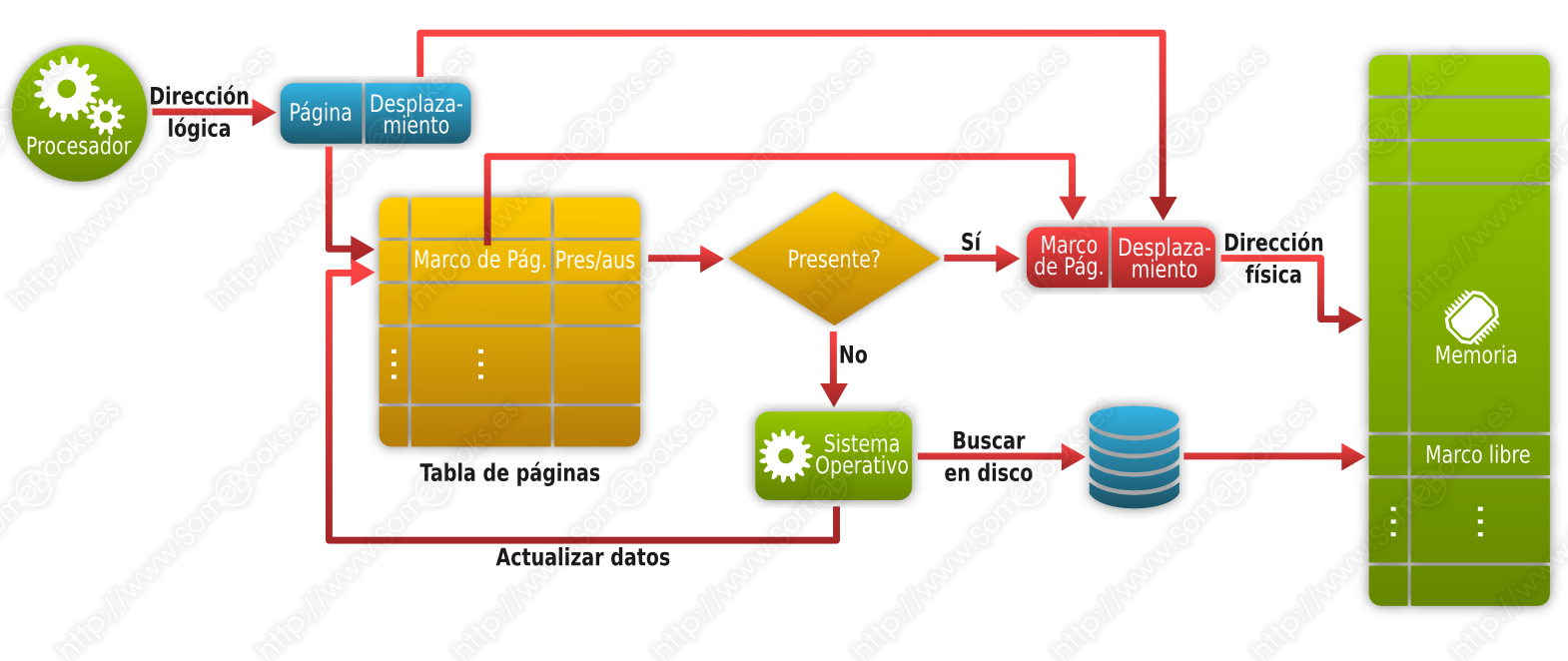
Este tipo de esquemas consiguen que la memoria se aproveche mucho mejor. Además, al poder cargar más procesos en la misma cantidad de memoria, el procesador estará mejor aprovechado. Sin embargo, si se produce una situación que provoque una cantidad elevada de fallos de página, los accesos a disco se multiplicarán y el rendimiento puede caer de forma considerable. Este fenómeno recibe el nombre de hiperpaginación.
Administración de la memoria
Los sistemas operativos modernos suelen realizar la mayor parte de la administración de memoria de forma automática y transparente. En cualquier caso, aún tenemos algunas cosas que podemos hacer para mejorar el rendimiento de nuestro sistema.
La cantidad mínima de memoria para instalar Windows 8.1 es de 1 GB (en sistemas de 32 bits) o 2 GB (en sistemas de 64 bits.
Por su parte, Ubuntu 14.04 LTS necesita un mínimo de 384 MB
Evidentemente, lo primero será saber si tenemos la suficiente cantidad de memoria instalada. En este sentido, debemos tener en cuenta que el mínimo recomendado por los fabricantes es eso, un mínimo. En realidad, para un uso cotidiano del sistema, siempre se recomienda, como mínimo, duplicar esa cantidad.
Otra precaución lógica será no ejecutar más programas de los necesarios en un determinado instante. Un ejemplo habitual: Estás trabajando con el procesador de textos y necesitas hacer una consulta en Internet. Abres el navegador, realizas la consulta y vuelves al procesador de textos… Pero dejas abierto el navegador.
Si lo cierras, liberas la memoria que está ocupando para que puedan usarla otros programas y el procesador, que no tendrá que dedicarle tiempo de proceso. Siempre podrás volver a abrirlo más tarde.
Relacionado con lo anterior, conviene mencionar todos esos complementos que embellecen el sistema, como las animaciones para abrir o cerrar ventanas, los relojes en el escritorio o los complementos de la barra de tareas que nos indican la predicción del tiempo. Todos ellos se están ejecutando en segundo plano y están consumiendo tiempo de procesador y capacidad de memoria, lo que significa que, si tu ordenador no ofrece el rendimiento que esperas, estos deben ser los primeros candidatos de los que prescindir.
Además de tener en cuenta los consejos básicos anteriores, también podemos aplicar algunas acciones como las que ya te hemos explicamos en los siguientes artículos de SomeBooks.es:
