Capítulo 4: Estructura del sistema operativo (Parte 1)

Gestión de procesos

La idea fundamental que tenemos de un sistema informático consiste en un dispositivo que es capaz de ejecutar ordenes agrupadas en forma de programas.
Mientras un programa no se encuentre en ejecución, no será nada más que un archivo de datos en un medio de almacenamiento.
En este sentido, podemos entender el concepto de proceso como un programa que se está ejecutando. Sin embargo, una definición más académica sería así:
Una unidad de actividad que ejecuta una secuencia ordenada de instrucciones, que dispone de una serie de recursos asignados por el sistema y que se encuentra en un estado particular.
Otro matiz a tener en cuenta es que un programa, entendido como un archivo que contiene órdenes, reside en la memoria secundaria del ordenador, mientras que un proceso reside en la memoria principal.
Todo proceso tiene asociado un espacio de direcciones en la memoria principal, donde se guardan las propias instrucciones del proceso y los datos que maneja. Además, el sistema dispondrá de una Tabla de procesos donde guarda la información relevante de cada proceso. Esta información puede variar según el sistema operativo del que hablemos pero, en general, nos encontraremos estos datos:
-
El identificador del proceso (PID, del inglés, Process IDentifier)
-
El estado del proceso, es decir, si se está ejecutando, o no.
-
Su prioridad con respecto al resto de los procesos del sistema.
-
La posición de memoria donde se encuentra.
-
Etc.
Dada su importancia, normalmente, los sistemas operativos se diseñan en torno al modo en el que manejan los procesos, tratando de resolver de la mejor forma posible las siguientes situaciones:
-
Ofrecer a los procesos los recursos que necesiten, atendiendo a una estrategia de asignación concreta (permisos, prioridad, evitar interbloqueos, etc.)
-
Repartir el tiempo de ejecución del procesador entre varios procesos, de forma que esté ocupado el mayor tiempo posible, ofreciendo la sensación de que los procesos se están ejecutando a la vez y permitiendo que todos ellos tengan un tiempo de respuesta adecuado.
-
Facilitar la creación de procesos por parte del usuario y de otros procesos, y la comunicación entre distintos procesos. La creación de un proceso hijo por parte de un proceso padre se denomina process spawning.
Un proceso puede crear otro proceso con el objetivo de estructurar su diseño o de aumentar su rendimiento. Por ejemplo, un servidor de impresión puede crear un nuevo proceso por cada documento a imprimir. De esta forma, el proceso padre se encarga de la recepción de documentos y cada proceso hijo se centra en imprimir un documento concreto.
¿Cómo se ejecuta un proceso?
Como hemos dicho antes, para que un proceso se ejecute, su secuencia de instrucciones debe encontrarse en la memoria principal. Además, en todos los sistemas operativos modernos, se va intercalando la ejecución de distintos procesos, de forma que se alternan el uso del procesador.
Para saber en qué posición de memoria se encuentra la siguiente instrucción que debe ejecutarse, el procesador dispone de un registro llamado Contador de programa (en inglés, Program Counter, o PC), que irá cambiando de valor según pase el tiempo.
La secuencia de valores que vaya teniendo el Contador de programa podrán apuntar a instrucciones de diferentes procesos.
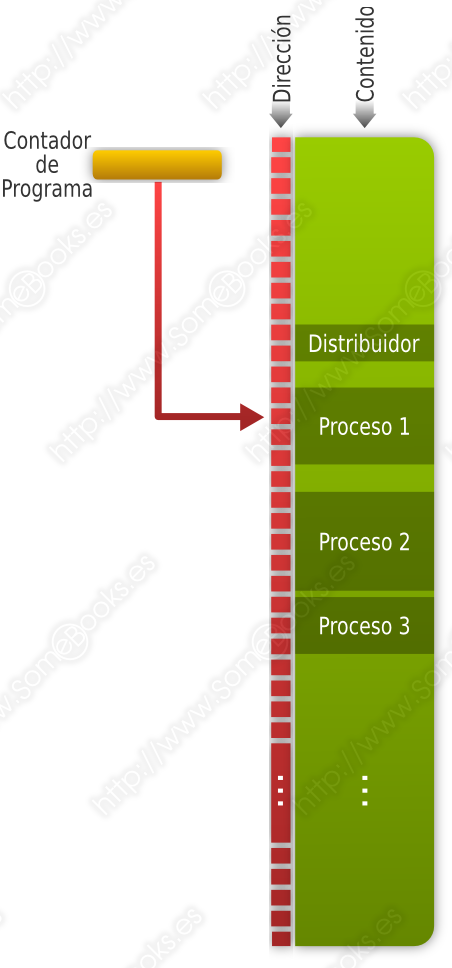
El procesador ejecutará el código perteneciente a un módulo del sistema operativo, llamado Distribuidor (en inglés, Dispatcher), cada vez que un proceso haya consumido su tiempo (medido en ciclos de instrucción) o haya solicitado algún servicio por el que deba esperar (p. ej. una operación de E/S).
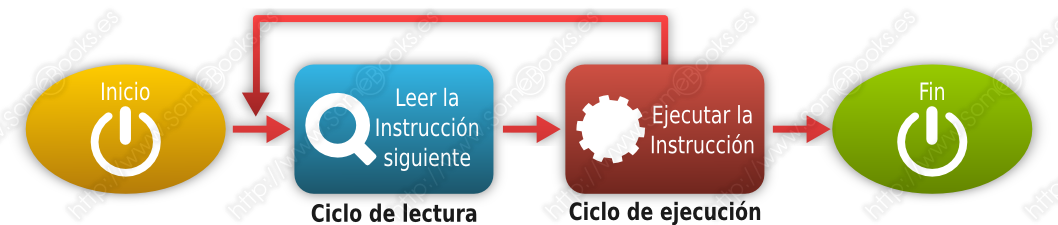
Como recordarás del capítulo 1, podemos definir un ciclo de instrucción como el tiempo que emplea el procesador en ejecutar una instrucción en lenguaje máquina y, de un modo simplificado, podríamos dividirlo en dos pasos:
-
El ciclo de lectura (en inglés, fetch), que consiste en cargar una instrucción desde la memoria principal a los registros del procesador
-
El ciclo de ejecución (en inglés, execute), que consiste en interpretar la instrucción (decodificarla) y ejecutarla, enviando las señales adecuadas a los componentes que deben realizar la operación que indica la instrucción.
Por este motivo, también suele llamarse ciclo de fetch-and-execute o fetch-decode-execute.
Llamamos multitarea o multiprogramación a la capacidad que tienen los sistemas operativos actuales de alternar el uso del procesador entre distintos procesos. Dada la velocidad a la que funcionan los procesadores, el usuario tiene la sensación de que los procesos se ejecutan al mismo tiempo.
Por otro lado, cuando en un sistema informático disponemos de varios procesadores (o incluso un único procesador con varios núcleos), pueden ejecutarse varios procesos al mismo tiempo. A esta técnica la llamamos multiproceso o multiprocesamiento. Cuando todos los procesadores (o núcleos) actúan en igualdad de condiciones, hablamos de multiproceso simétrico o SMP (del inglés Symmetric Multi-Processing). Cuando el sistema dispone de procesadores con funciones especializadas, hablamos de multiproceso asimétrico o AMP (del inglés, Asymmetric Multi-Processing).
¿Cómo se intercalan los procesos?
Ya hemos dicho más arriba que el procesador ejecutará el código perteneciente a un módulo del sistema operativo, llamado Distribuidor, cada vez que un proceso haya consumido su tiempo o haya solicitado algún servicio por el que deba esperar. Así se evita que un proceso se apropie del procesador de forma indefinida.
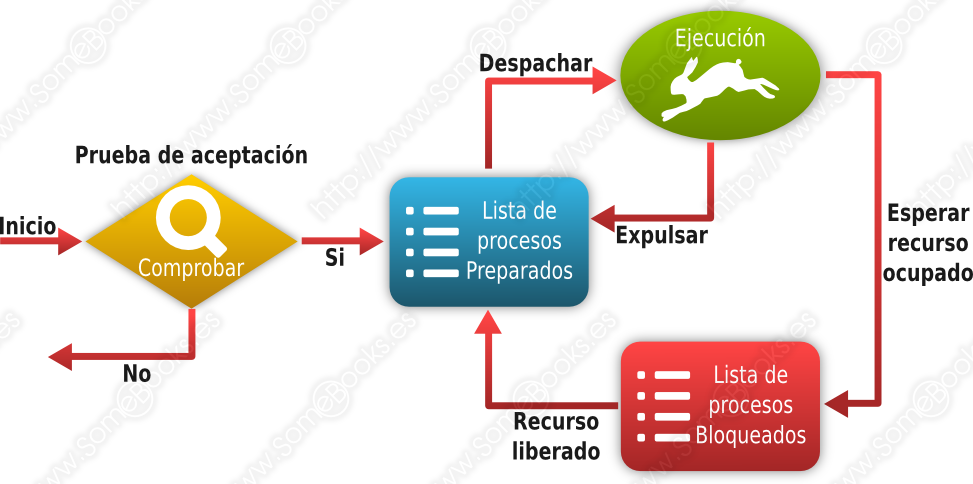
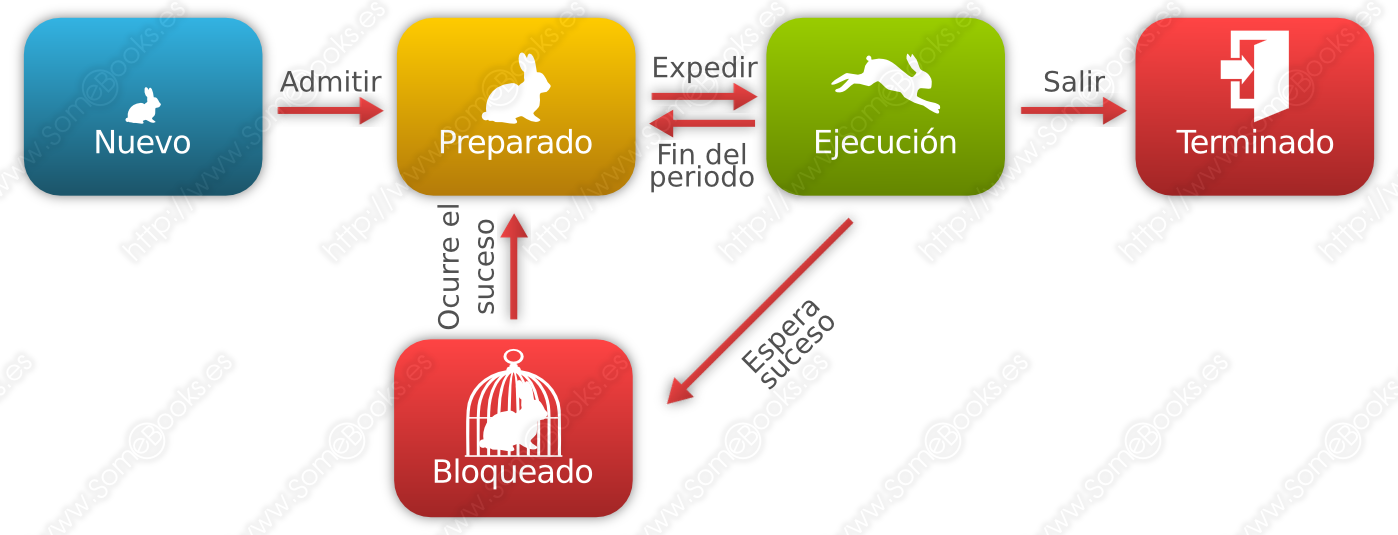
De la idea anterior, podemos deducir que un proceso en particular puede encontrarse en tres situaciones diferentes:
-
En ejecución: En este estado se encontrará el proceso que ocupa la atención del procesador en ese momento. Si el ordenador dispone de varios procesadores, o varios núcleos, podrá existir un proceso en ejecución por cada uno de los núcleos presentes.
-
Preparado: En este estado se encuentran los procesos que no se están ejecutando, pero que podrían hacerlo en cualquier momento y sólo esperan su oportunidad para hacerlo.
-
Bloqueado: En este estado estarán los procesos que han solicitado algún servicio del sistema operativo y están esperando una respuesta.
Aunque no vamos a entrar en muchos detalles, también podríamos definir un estado Nuevo en el que se encontraría un proceso cuando acaba de crearse.
En esta situación, el proceso aún no estaría incluido en el grupo de procesos Preparados y el sistema operativo aún no se habría comprometido a ejecutarlo. Tampoco estaría cargado en memoria.
Durante este estado, el sistema analizaría si dispone de los recursos necesarios para admitir su ejecución.
También podríamos tener procesos que se encuentren descargados a memoria secundaria, de manera temporal, con el objetivo de liberar la porción que ocupaban de memoria principal. En este caso, diremos que se encuentra en estado Suspendido (volveremos a hablar de este aspecto en el apartado destinado a la Gestión de memoria principal).
En la siguiente imagen vemos un proceso que se encuentra actualmente en ejecución, otro que se encuentra bloqueado en espera de poder utilizar la impresora y un tercero que se encuentra suspendido (no está usando la memoria principal, aunque la tiene solicitada):
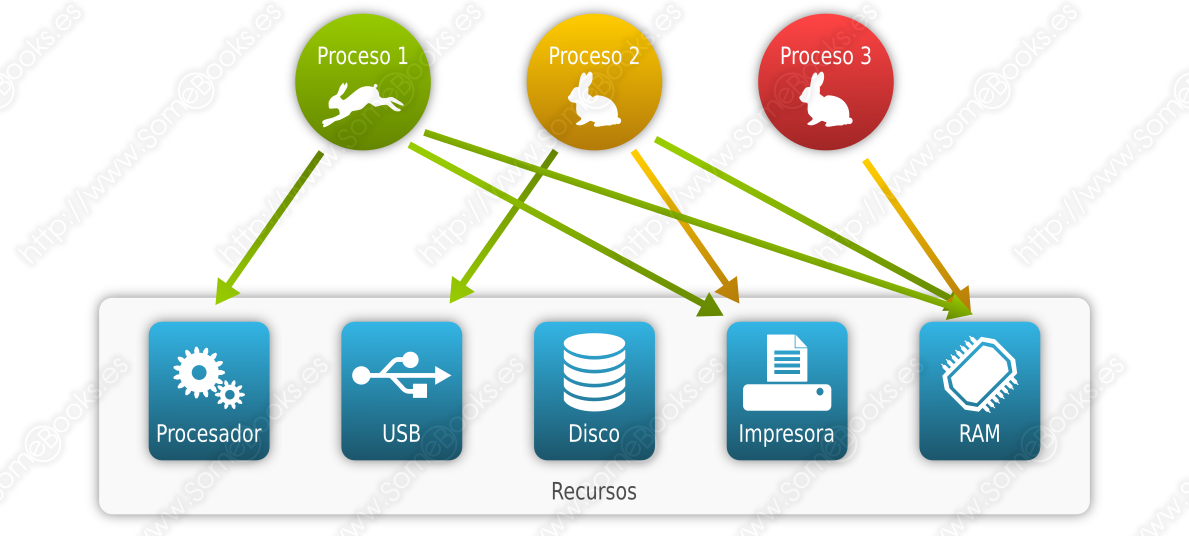
En relación a esto, es importante que el sistema operativo trate de evitar el interbloqueo (en inglés, deadlock), que consiste en que dos procesos diferentes necesitan los dos mismos recursos y cada uno de ellos tiene uno asignado. Ambos estarán bloqueados en espera de que se libere el recurso que aún no tienen y, por lo tanto, ninguno liberará el recurso que ya poseen.
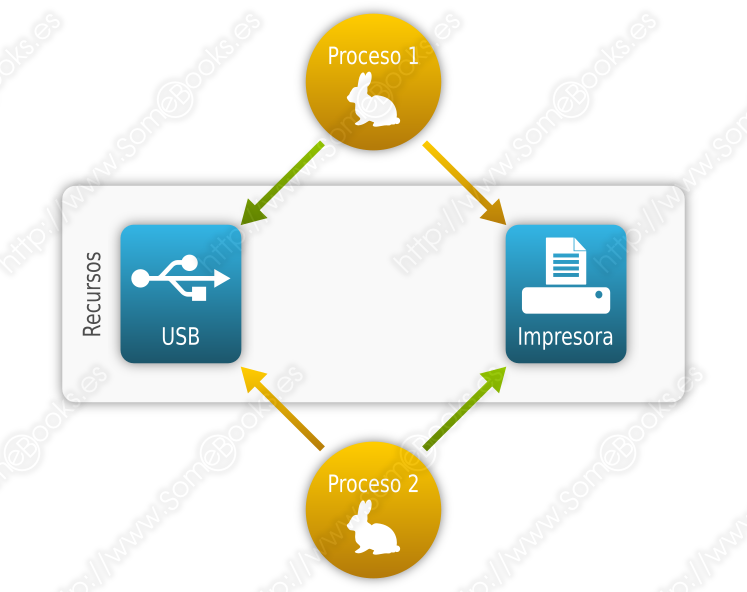
Aunque el ejemplo más evidente de interbloqueo se produce entre dos procesos, las situaciones más difíciles de predecir y solucionar implican múltiples procesos y recursos.
Cada vez que se crea un nuevo proceso, este es situado en estado de Preparado.
Cuando el proceso que se está ejecutando es interrumpido, el Distribuidor elige un nuevo proceso entre los que se encuentran en estado Preparado. El estado del proceso elegido pasa a ser En ejecución mientras que el proceso que abandona la ejecución pasará a estado Preparado (si ha consumido su tiempo) o Bloqueado (si ha realizado una petición al sistema).
Los procesos que se encuentran en estado Preparado aguardan su turno en una cola.

Llamamos Traza de un proceso al listado de la secuencia de instrucciones que se ejecutan para dicho proceso.
Se puede estudiar el comportamiento que está teniendo un procesador analizando el modo en el que se intercalan las trazas de los diferentes procesos activos.
Cuando se ejecuta el módulo del kernel que se encarga de parar la ejecución de un proceso y realizar los cambios necesarios para que se ejecute un proceso diferente, decimos que se ha producido un cambio de contexto.
Un cambio de contexto lleva a cabo las siguientes acciones:
-
Guarda en la memoria principal el valor de los registros del procesador para el proceso que se estaba ejecutando.
-
Recupera el valor de los registros del procesador, desde la memoria principal, para el proceso que toma el relevo. El proceso elegido dependerá del Planificador del sistema operativo, que aplicará una determinada política para elegirlo (turno, prioridad, etc.).
-
Se ejecuta la instrucción indicada en el Contador de Programa, que forma parte del contexto que acabamos de recuperar y, por lo tanto, será la siguiente del nuevo proceso.
Como podemos deducir de lo dicho hasta ahora, los posibles cambios de estado son:
-
Inicio a Nuevo: Se crean las estructuras de datos del proceso que representa a un programa, para poder ejecutarlo.
-
Nuevo a Preparado: Se produce cuando el sistema está listo para aceptar al nuevo trabajo. Los sistemas operativos suelen limitar la llegada de procesos nuevos para evitar que se degrade el rendimiento del sistema.
-
Preparado a En ejecución: El sistema operativo elige uno de los procesos en estado Preparado.
-
En ejecución a Terminado: El proceso se finaliza cuando acaba su tarea o si lo abandona su proceso padre.
-
En ejecución a Preparado: El proceso ha consumido el tiempo de ejecución que tenía asignado por el sistema operativo. También puede haber cedido el control o haber sido interrumpido por un proceso con una prioridad más elevada.
-
En ejecución a Bloqueado: El proceso solicita un recurso (normalmente a través de una llamada a un servicio del sistema operativo) y no puede serle asignado en ese momento.
-
Bloqueado a Preparado: El sistema operativo se encuentra en disposición de otorgar el recurso solicitado por el proceso.
-
Preparado a Terminado / Bloqueado a Terminado: Cuando se trata de un proceso hijo, su proceso padre puede finalizarlo en cualquier momento. También puede finalizar un proceso hijo cuando finaliza su proceso padre..
¿Cuándo acaba un proceso?
Todos los sistemas operativos deben tener un mecanismo para identificar cuando termina un proceso. Si se trata de un script o un proceso por lotes (batch) concluirá cuando acaben sus instrucciones o cuando se encuentre una orden de parada (Halt). Si es un proceso interactivo, será el usuario el que elija el momento de terminar.
Además, un proceso puede verse interrumpido abruptamente por diversos motivos. Entre ellos, podemos encontrar los siguientes:
-
Sobrepasar el tiempo de ejecución asignado al proceso (tiempo real, de uso del procesador, etc.) o el tiempo máximo de espera ante un suceso.
-
No disponer de memoria suficiente para satisfacer las solicitudes del proceso
-
Que el proceso trate de acceder a posiciones de memoria o recursos del sistema que no tiene autorizados.
-
Que una de sus instrucciones contenga un error aritmético o los datos no sean del tipo o tamaño adecuado.
-
Que surja un error en una operación de entrada/salida (no existe un archivo, se produce un error de lectura, etc.)
-
Que una instrucción del programa no exista en el juego de instrucciones o que sea una instrucción reservada al sistema operativo.
-
Que el sistema operativo, el usuario o el proceso padre decida terminarlo. También suelen terminar los procesos hijos cuando termina el proceso padre.
Lógicamente, cuando un proceso termina, abandona su estado (En ejecución, Preparado, Bloqueado) y es eliminado de la cola o colas que dependan del Distribuidor.
Cuando un proceso acaba, puede definirse un nuevo estado, del que no hemos hablado aún. Lo llamaremos Terminado y será el estado en el que se encuentre un proceso que ha sido eliminado del grupo de procesos ejecutables por cualquiera de los motivos anteriores.
Este estado se mantendrá mientras se liberan sus tablas de información, su memoria y cualquier otro dato que haya sido necesario para su ejecución.
Si el proceso colaboraba con otros, también puede almacenar información necesaria para ellos, y se les dará la oportunidad de obtenerlos antes de que sean eliminados.
Planificación de procesos
Una de las claves para que un sistema multiprogramado sea eficaz es la Planificación de procesos, que consiste en ir asignando procesos al procesador (o procesadores / núcleos) a lo largo del tiempo, de forma que se cumplan los objetivos en varios aspectos:
-
Rendimiento: Trata de maximizar el número de acciones que se completan en un plazo de tiempo determinado.
-
Tiempo de respuesta: El sistema debe responder a las solicitudes de los usuarios en un tiempo adecuado.
-
Tiempo de retorno: El sistema debe ofrecer resultados de los procesos por lotes en un tiempo adecuado.
-
Equidad: Todos los procesos deben ser considerados según sus características.
-
Eficiencia: Se debe aspirar a que el procesador esté activo constantemente.
Como cabe esperar, el módulo del sistema operativo que se encarga de esta tarea se denomina Planificador (en inglés, Scheduler).
Según el diseño del sistema operativo, el Planificador utilizará unos criterios u otros para llevar a cabo su tarea. Estos criterios reciben el nombre de Algoritmos de Planificación (o también, Políticas de Planificación).
Una política de planificación es no apropiativa (en inglés, non-preemptive) cuando, una vez que un proceso toma el control del procesador, no lo abandona hasta que termina o hasta que se bloquea. Será apropiativa (en inglés, preemptive) cuando el sistema puede interrumpir el proceso para ejecutar otro diferente.
A continuación, nombramos los más importantes:
Primero en llegar primero en ser servido, o FCFS (del inglés, First Come First Served)
Se emplea en procesos por lotes (sin intervención del usuario) y es no apropiativo. Los procesos se van poniendo en cola según llegan y se les asigna el estado Preparado. Cuando es asignado al procesador, no lo abandona hasta que termina.
Una de sus ventajas principales consiste en que es un algoritmo muy sencillo de implementar y también es fácilmente predecible.
Entre sus principales inconvenientes podemos mencionar que los procesos largos pueden hacer esperar mucho a los procesos cortos y que el tiempo de servicio mínimo variará mucho según el número de procesos ejecutados y la duración de los mismos. Además, el tiempo medio de espera depende de que lleguen antes los procesos más cortos o los más largos.
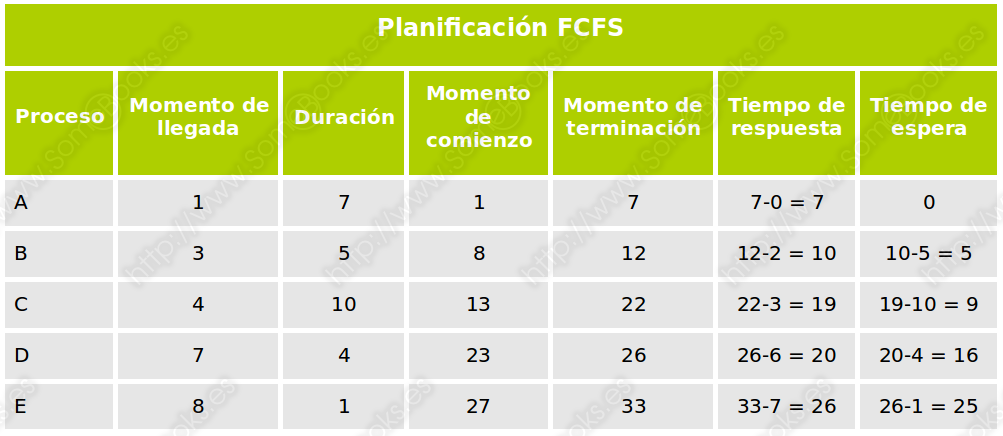
Para entender su funcionamiento, podemos estudiar el siguiente ejemplo práctico en el que disponemos de cinco procesos que se incorporan al sistema en momentos sucesivos y que tienen diferentes tiempos de duración:
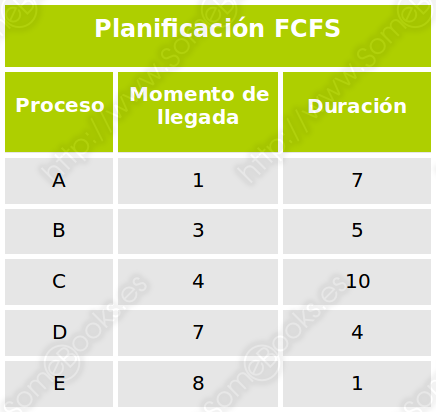
Si analizamos de forma gráfica el comportamiento del sistema, observaremos que se comporta del siguiente modo.
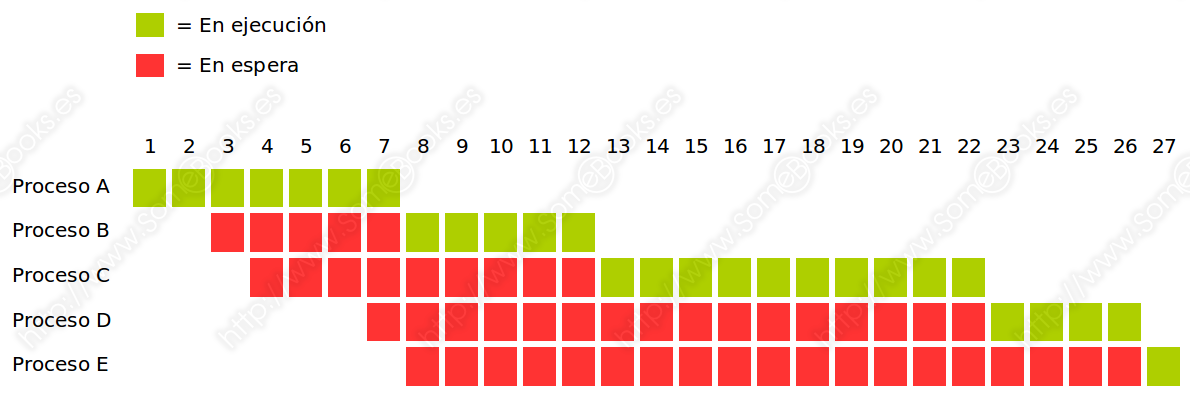
En consecuencia, podemos extraer las siguientes conclusiones:
Primero el más corto, o SJF (del inglés, Shortest Job First)
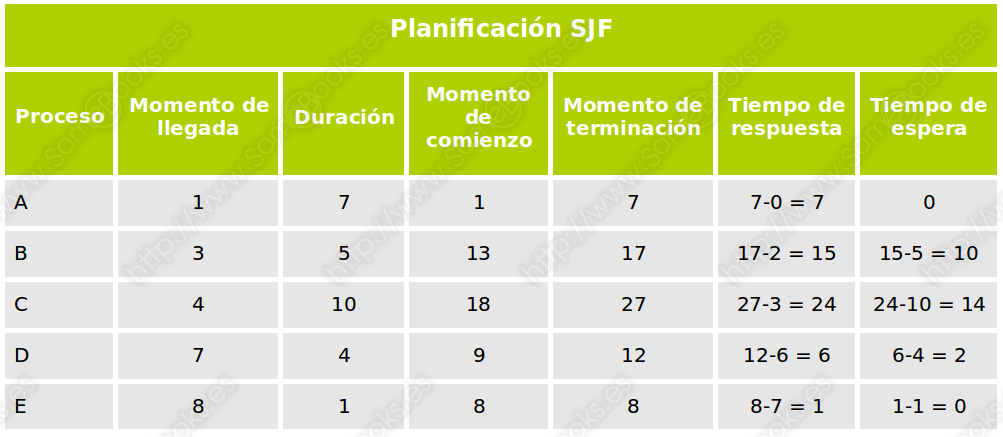
Se emplea en procesos por lotes (sin intervención del usuario) y es no apropiativo. Los procesos se van poniendo en cola según llegan y se les asigna el estado Preparado, pero el Planificador elige el que tiene un menor tiempo previsto de ejecución.
Como en el caso anterior, podemos estudiar un ejemplo práctico para entender su funcionamiento. En este caso, partiremos de los mismos datos, para que puedas comparar los resultados:

Y analizando los resultados, obtendríamos la siguiente tabla:
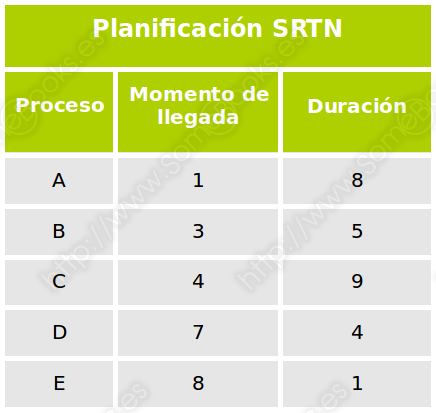
Existe una versión apropiativa de este algoritmo denominada Primero el de menor tiempo restante, o SRTN (del inglés, Shortest Remaining Time Next). En este caso, si un proceso bloqueado pasa al estado Preparado, el distribuidor comprueba si su tiempo restante es inferior que el del proceso que se encuentra en ejecución. En caso afirmativo, éste toma el control del procesador y el proceso que está ejecutándose pasa al estado Preparado.
Aunque es un algoritmo muy eficaz para los procesos cortos, resulta difícil predecir los intervalos de asignación del procesador e, incluso, puede haber procesos largos que sufran de inanición, es decir, que no lleguen a ejecutarse mientras existan procesos cortos esperando turno.
Como antes, lo ilustraremos con un ejemplo. En este caso, hemos cambiado ligeramente los datos iniciales para que sea más ilustrativo:
Y el gráfico resultante quedará como sigue:

De nuevo, aquí tienes los datos arrojados, representados en forma de tabla:

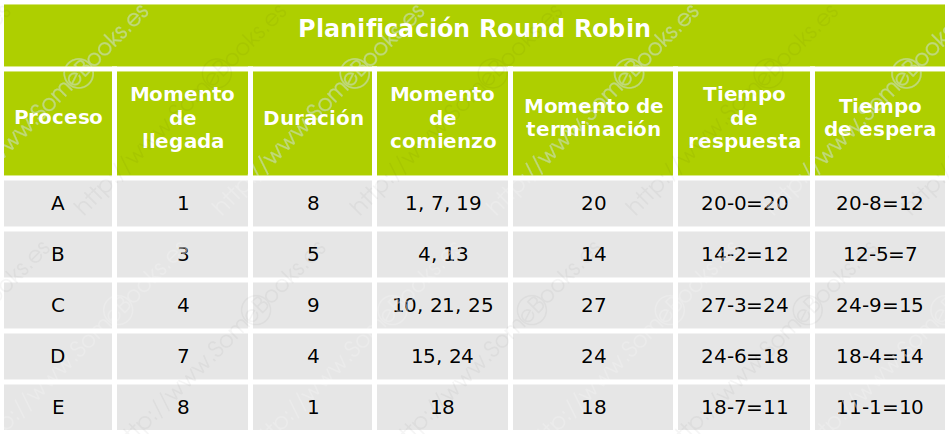
Por turnos, o RR (del inglés, Round Robin)
Se emplea en procesos interactivos (en los que interviene el usuario) y es apropiativo. Los procesos se van poniendo en cola según llegan y se les asigna el estado Preparado. El procesador se irá asignando a cada proceso, por orden, durante una fracción de tiempo llamada Quantum, que es igual para todos. Si el proceso se acaba, se bloquea, o si se agota su tiempo, el procesador es liberado para el siguiente proceso de la lista.
Por lo tanto, la cola de procesos actúa como una estructura circular con organización FIFO.
Para ilustrarlo, comenzaremos por los mismos datos de entrada del ejemplo anterior, suponiendo un Quantum equivalente a tres unidades de tiempo. El resultado sería como el que muestra la siguiente imagen:
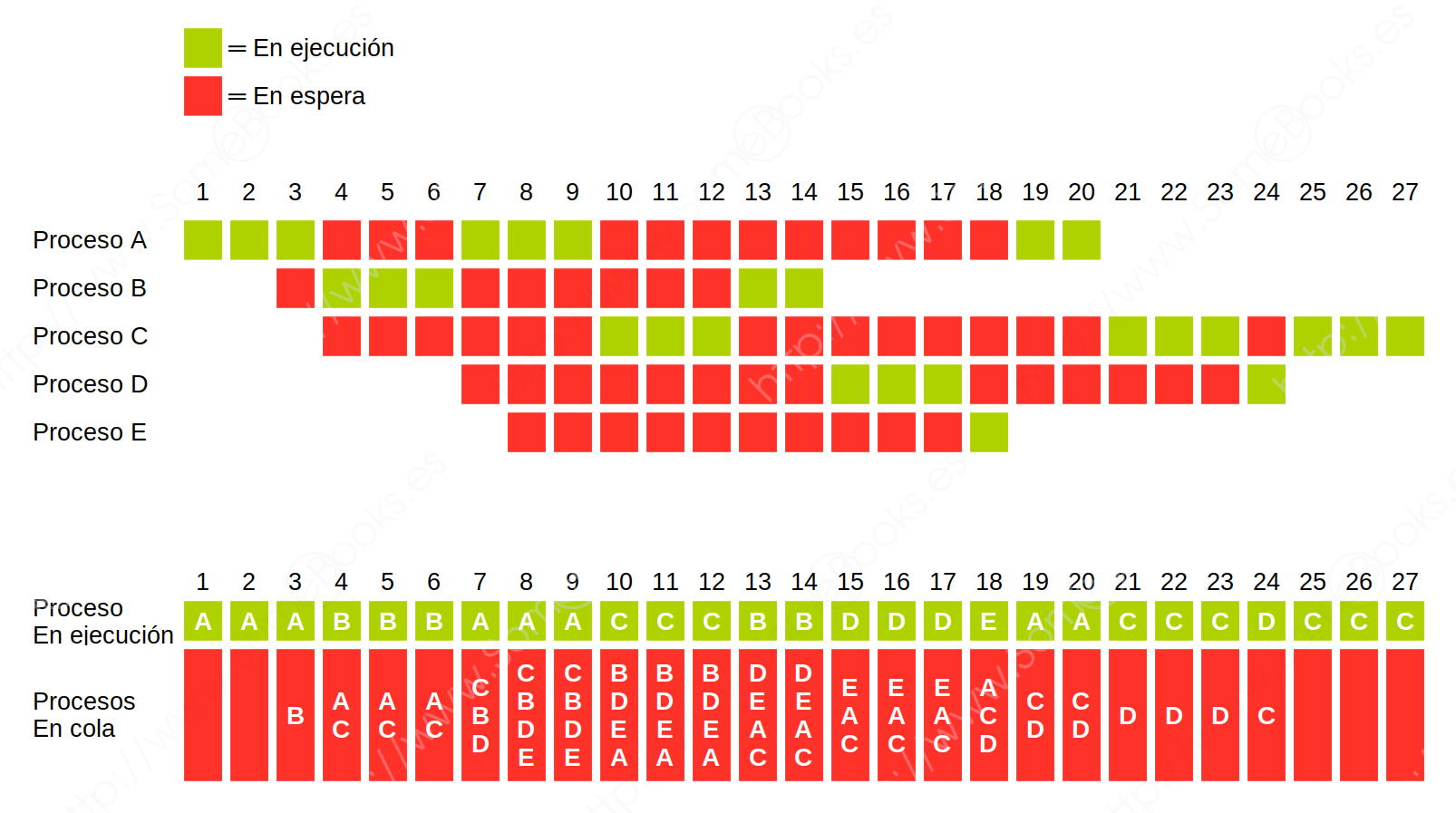
Para facilitar la comprensión, hemos incluido también una representación gráfica de los procesos que se encuentran en cola para ser ejecutados y del proceso que se encuentra en ejecución en cada unidad de tiempo.
Finalmente, la siguiente tabla muestra los datos que ofrece:
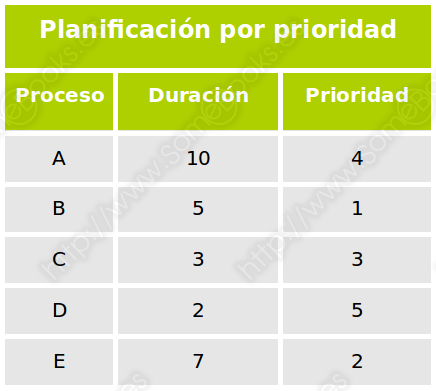
Planificación por prioridad
Se emplea en procesos interactivos (en los que interviene el usuario) y es apropiativo. A cada proceso se le asigna un número entero que representa su prioridad, de modo que, cuanto menor es el número, mayor es la prioridad.
Si se considera un algoritmo no apropiativo, funcionaría como el algoritmo Primero el más corto (SJF), pero considerando la prioridad en lugar de la duración.
Aún así, veamos un ejemplo, suponiendo que todos los procesos están disponibles desde el primer momento. Estos serían nuestros datos de partida
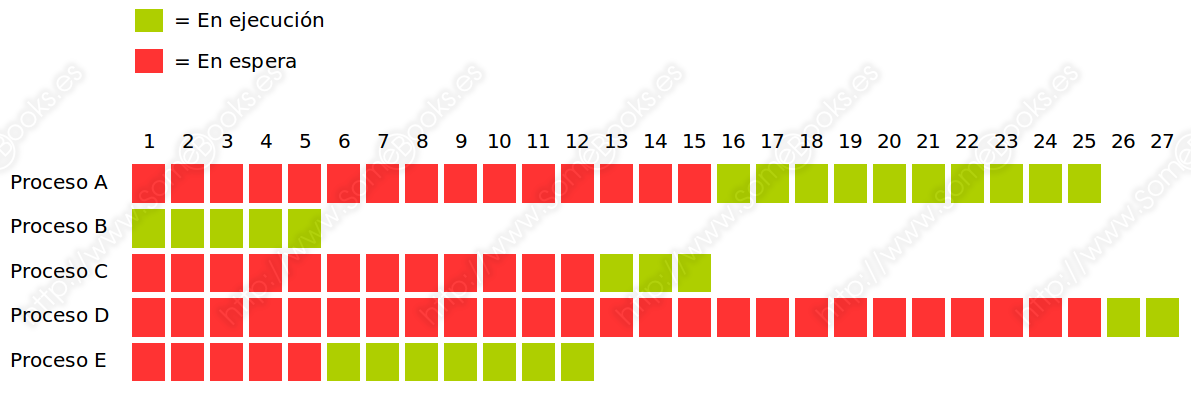
Siguiendo la asignación del procesador según el orden de prioridad (el más bajo primero), obtendríamos el siguiente gráfico:
Finalmente, en la siguiente tabla recogemos los datos numéricos obtenidos:
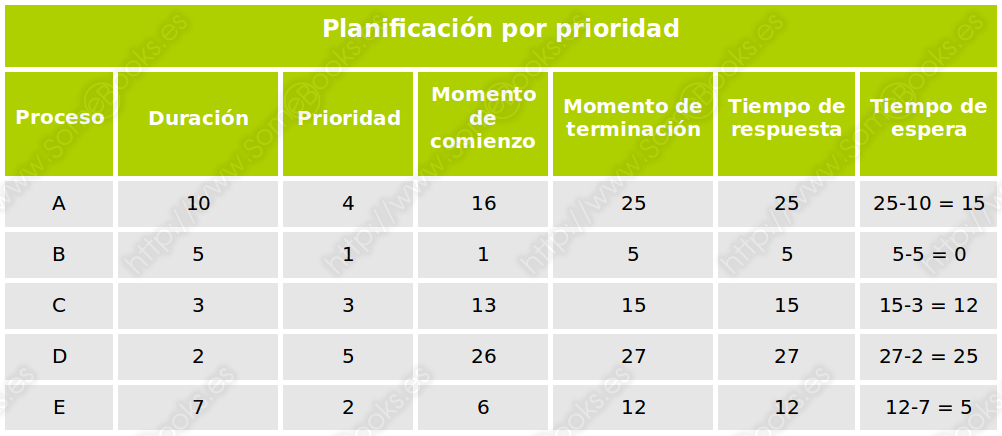
Para evitar que los procesos con una prioridad más elevada monopolicen el uso del procesador (y los de prioridad más baja padezcan inanición), la prioridad de los procesos puede ir reduciéndose cada vez que obtengan el uso del procesador. Así, se convertiría en una versión apropiativa que funcionaría como Primero el de menor tiempo restante (SRTN), pero tomando la prioridad en lugar de la duración y disminuyéndola cada vez.
Como hemos comentado más arriba, en el caso de que los procesos puedan tener diferentes prioridades, el Planificador elegirá siempre al proceso de mayor prioridad para su ejecución. Y en el caso de que existan varios procesos con el mismo grado de prioridad, es común que se establezca un turno rotatorio entre ellos.
El modo de implementar esta característica puede consistir en mantener una cola de procesos en estado Preparado para cada uno de los posibles niveles de prioridad.
Como hemos dicho más arriba, para evitar que los procesos con menor prioridad puedan padecer inanición, en los procesos de mayor prioridad, ésta puede ir degradándose en función de su antigüedad o de la frecuencia con la que hayan obtenido el uso del procesador.
Por lo tanto, el esquema sobre los estados de un proceso que vimos al principio podría quedar como sigue:
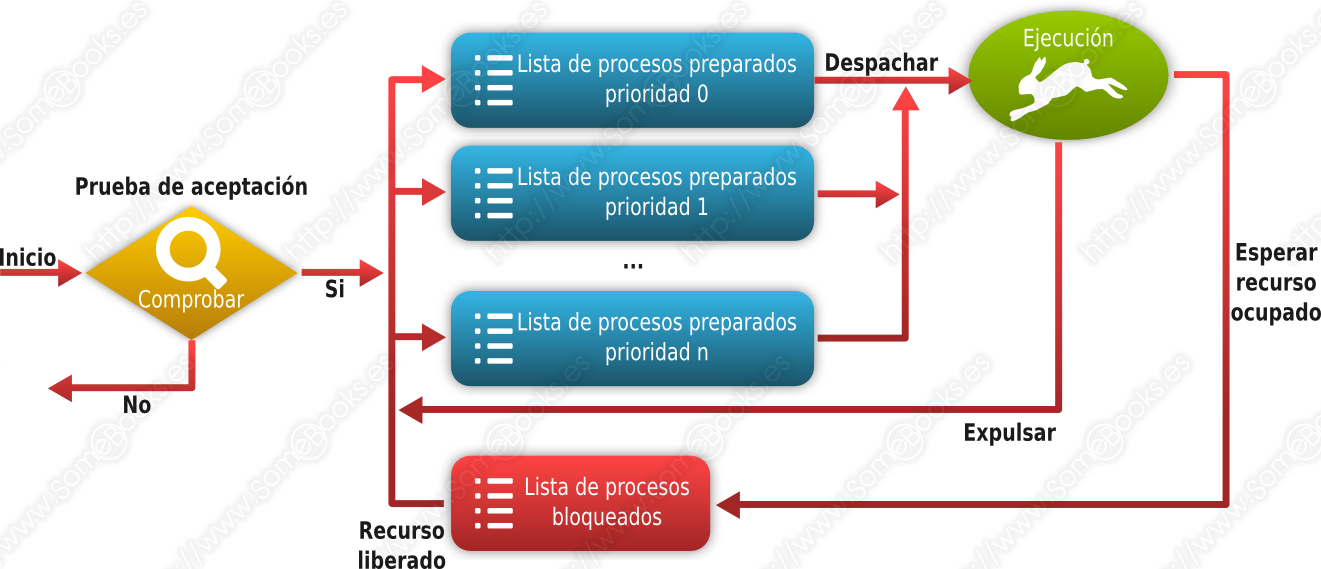
Planificación por reparto equitativo, o FSS (del inglés, Fair-share Scheduling)
Se emplea en procesos interactivos (en los que interviene el usuario) y es apropiativo. Se tiene en cuenta el número de usuarios que serán atendidos, de modo que el tiempo de ejecución se reparte entre ellos de forma equitativa. La ejecución del conjunto de procesos de cada usuario no sobrepasará el tiempo asignado a dicho usuario.
Este concepto puede ampliarse a grupos de usuarios, de modo que las decisiones de planificación otorguen a cada grupo de usuarios un servicio equivalente. De este modo, el uso intensivo del sistema por parte de un grupo de usuarios no perjudicará a los demás grupos.
Planificación de Colas Múltiples, o MQS (del inglés, Multilevel Queue Scheduling)
Se emplea tanto en procesos interactivos como en procesos por lotes (en los que no interviene el usuario) y es apropiativo. Consiste en fragmentar la cola de procesos en estado Preparado en varias colas más pequeñas, de modo que cada una puede estar administrada por un algoritmo de planificación diferente. De este modo, cada proceso será asignado a una determinada cola en función de sus características pudiendo tratar de manera diferente, por ejemplo, a los procesos interactivos y a los procesos por lotes.
Del mismo modo que en algunas situaciones puede ser interesante contemplar diferentes colas de procesos en estado Preparado, puede ser conveniente disponer de una cola de procesos en estado Bloqueado para cada tipo de suceso. De esta forma, el sistema evita recorrer toda la lista de bloqueados para localizar el proceso que está esperando un suceso concreto.
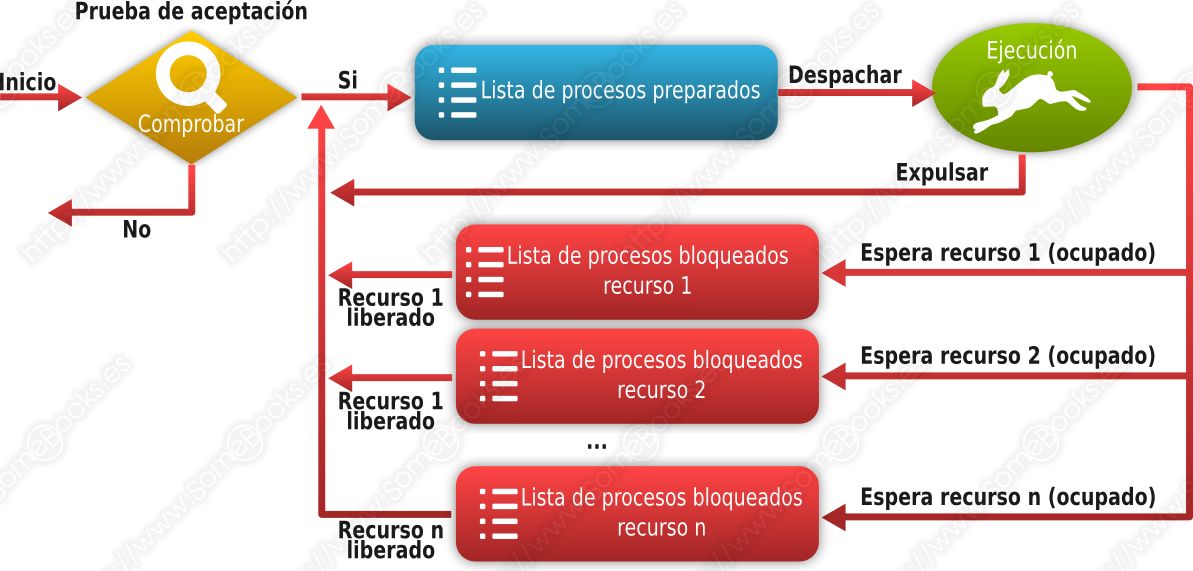
Comunicación entre procesos
En muchas ocasiones, un sistema operativo ejecuta varios procesos que deben comunicarse entre ellos para colaborar en un objetivo común. Para lograrlo, el sistema puede ofrecer una serie de funciones llamadas IPC (del inglés, Inter-Process Communication) que facilitan el envío de mensajes entre los procesos para comunicarse y sincronizarse.
Otra forma que tienen los procesos de comunicarse entre sí es compartiendo determinadas zonas de memoria.
Cuando los procesos que necesitan comunicarse están en ordenadores diferentes, se utiliza RPC (del inglés, Remote Procedure Call). Sin embargo, quien programa dichos procesos no tendrá que preocuparse de su ubicación física y de los aspectos que deriven de esa circunstancia. Para ellos, no habrá diferencia con la comunicación con procedimientos locales. Es decir, será el sistema operativo quien se encargue de resolver los problemas que se deriven de esta situación.
Procesos y servicios
En los sistemas operativos existe un tipo de proceso con características particulares a los que suele llamarse Servicios. Este tipo de procesos suele ejecutarse en segundo plano, es decir, sin que el usuario tenga constancia directa de su presencia y, normalmente, esperan un tipo de suceso para ofrecer una determinada prestación al usuario.
En el mundo GNU/Linux, los servicios suelen recibir el nombre de demonios (en inglés, daemons, de Disk And Execution MONitors).
Por ejemplo, el servicio de impresión se encarga de administrar todas las solicitudes de los diferentes programas para usar la impresora. Normalmente, no tendremos constancia de que se está ejecutando. Salvo que se produzca algún incidente, lo único que comprobamos es que el trabajo de impresión se realiza correctamente, incluso cuando varios programas traten de imprimir un documento al mismo tiempo.
Es muy común que un servicio no ofrezca información sobre su funcionamiento a través de la pantalla, sino que suelen utilizarse archivos de registro donde realizan anotaciones (conocidos como archivos “log”, cuya traducción, más o menos literal al español, puede ser “anotar”).
Administración de procesos
Aunque muchas de las acciones que se aplican sobre los procesos las hace el sistema operativo de forma transparente, en SomeBooks.es ya hemos hablado con anterioridad de algunas de las cosas que sí podemos hacer nosotros como administradores. Son las siguientes:
Aunque, si prefieres recurrir a la línea de comandos, puedes echar un vistazo a estos artículos, que son válidos para diferentes versiones de Windows:
- Administrar procesos desde la línea de comandos de Windows 8.1 (válido para Windows 10).
- Administrar procesos con PowerShell.
